월, 화는 프로젝트 수행했습니닷
프로젝트 회고에 내용 적었습니닷
이번 주 내용은 드디어 내가 배워보고 싶었던 spark
뭔지도 잘 모르지만 내가 봤던 공고들에 항상 hadoop, spark활용능력이 자격 요건이나 우대사항에 있었던 것 같아서 배우고 싶었다.
먼저 제플린, 아파치 스파크, 자바를 설치했다.
- 제플린 (Zeppelin): 웹 기반의 데이터 분석과 시각화 도구로, 다양한 데이터 소스와 분석 언어를 지원하며 대화형 노트북을 제공.
- 아파치 스파크 (Apache Spark): 대규모 데이터 처리와 분석을 위한 분산 처리 엔진으로, 빠르고 유연한 데이터 처리를 지원하며 머신러닝, 스트리밍, SQL 등 다양한 기능을 제공.
- zeppelin
공식홈페이지를 참고하여 설치할 수 있다.
Zeppelin
SQL Zeppelin lets you connect any JDBC data sources seamlessly. Postgresql, Mysql, MariaDB, Redshift, Apache Hive and so on. USE NOW
zeppelin.apache.org
# 설치
$ wget https://dlcdn.apache.org/zeppelin/zeppelin-0.11.1/zeppelin-0.11.1-bin-all.tgz
# 압축 풀기
$ tar -xvf zeppelin-0.11.1-bin-all.tgz
$ mv zeppelin-0.11.1-bin-all ~/app/
# 실행
$ cd ~/app/zeppelin-0.11.1-bin-all
$ bin/zeppelin-daemon.sh start
$ jps
$ bin/zeppelin-daemon.sh stop
$ jps
$ bin/zeppelin-daemon.sh start
$ jps
$ bin/zeppelin-daemon.sh restart
$ jps
# 로그확인
$ tail -f logs/zeppelin--Playdata.log
우선은 잘 실행되지 않았다. start를 수행해도 failed가 떴다.
그래서 자바가 필요하다고 했었나..? 잘은 모르는 부분인데 아무튼 자바를 먼저 설치해주었다.
$ sudo apt update;sudo apt upgrade
# 다운받을 수 있는게 어떤게 있는지 확인하는 명령
$ apt-cache search openjdk | grep 17
openjdk-17-dbg - Java runtime based on OpenJDK (debugging symbols)
openjdk-17-demo - Java runtime based on OpenJDK (demos and examples)
openjdk-17-doc - OpenJDK Development Kit (JDK) documentation
openjdk-17-jdk - OpenJDK Development Kit (JDK)
openjdk-17-jdk-headless - OpenJDK Development Kit (JDK) (headless)
openjdk-17-jre - OpenJDK Java runtime, using Hotspot JIT
openjdk-17-jre-headless - OpenJDK Java runtime, using Hotspot JIT (headless)
openjdk-17-jre-zero - Alternative JVM for OpenJDK, using Zero
openjdk-17-source - OpenJDK Development Kit (JDK) source files
$ sudo apt install openjdk-17-jdk
# 확인
$ which java
/usr/bin/java
$ ls -l /usr/bin/java
lrwxrwxrwx 1 root root 22 Aug 7 11:46 /usr/bin/java -> /etc/alternatives/java
$ ls -l /etc/alternatives/java
lrwxrwxrwx 1 root root 43 Aug 7 11:46 /etc/alternatives/java -> /usr/lib/jvm/java-17-openjdk-amd64/bin/java
$tail -n 3 ~/.zshrc
# JAVA
export JAVA_HOME=/usr/lib/jvm/java-17-openjdk-amd64
export PATssH=$JAVA_HOME/bin:$PATH
$ source ~/.zshrc
/opt/homebrew/opt/openjdk@11/bin/java
그리고 제플린 설정을 바꿔주었다. 우리는 에어플로우로 이미 8080 포트를 사용하고 있었기 때문에 9999로 바꿔주고 서버 주소도 0.0.0.0으로 설정했다. 아, 필기를 보니 위에서 실패 뜬거는 이렇게 해서 해결했었던 것 같다. 이제 localhost:9999로 제플린 서버에 접속할 수 있다!
$ cd conf
$ cp zeppelin-site.xml.template zeppelin-site.xml
$ vi zeppelin-site.xml
<property>
<name>zeppelin.server.addr</name>
#<value>127.0.0.1</value>
<value>0.0.0.0</value>
<description>Server binding address. If you cannot connect to your web browser on WSL or Windows, change 127.0.0.1 to 0.0.0.0. It, however, causes security issues when you open your machine to the public</description>
</property>
<property>
<name>zeppelin.server.port</name>
#<value>8080</value>
<value>9999</value>
<description>Server port.</description>
</property>
# 에어플로우랑 포트랑 그런거 겹쳐서 안되는 것.
# 바꾸고 다시 start 하고 status 보니까 실행 잘 됨.
# 로그 보면 done이라고 잘 나와있음
다음은 spark 설치
https://www.apache.org/dyn/closer.lua/spark/spark-3.5.1/spark-3.5.1-bin-hadoop3.tgz
Apache Download Mirrors
<!-- This document is currently not in use, but should be kept in sync with https://www.apache.org/dyn/closer.html for future use --> We suggest the following location for your download: https://dlcdn.apache.org/spark/spark-3.5.1/spark-3.5.1-bin-hadoop3.tg
www.apache.org
이것도 공식 문서 참고
$ cd ~/tmp/down
$ wget https://dlcdn.apache.org/spark/spark-3.5.1/spark-3.5.1-bin-hadoop3.tgz
$ tar -xvf spark-3.5.1-bin-hadoop3.tgz
$ mv spark-3.5.1-bin-hadoop3 ~/app/
$ vi ~/.zshr
# SPARK_HOME
export SPARK_HOME=/home/sujin/app/spark-3.5.1-bin-hadoop3
그리고 spark와 제플린이 잘 연결됐는지 확인하기 위해 제플린에 다시 접속하여 명령어 입력
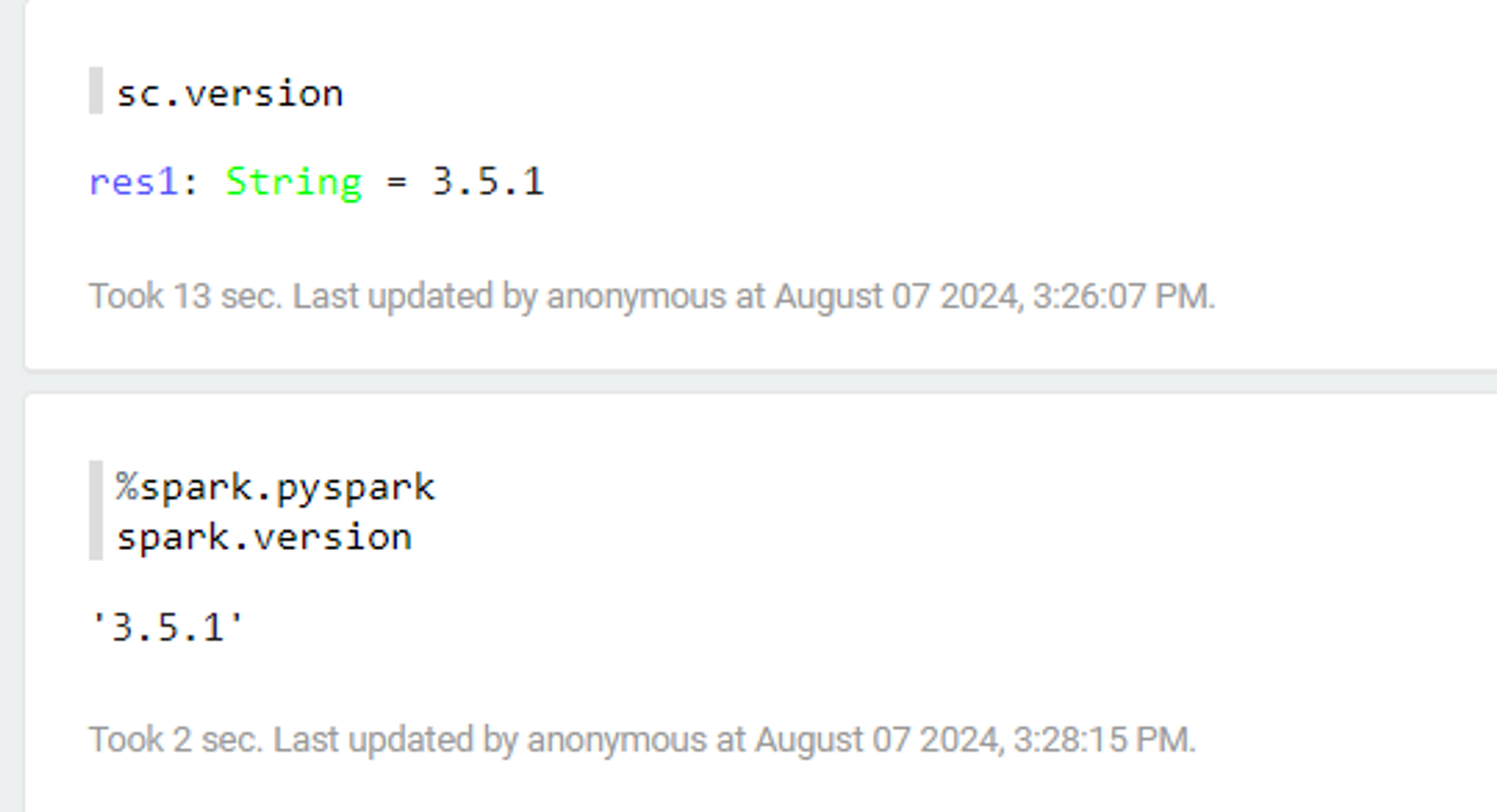
sc.version실패!
강사님이 찾으신 해결법으로 ~/app/zeppelin-0.11.1-bin-all/interpreter/spark
이 경로에 있는 pyspark, python, scala 안에 ._ 으로 시작하는 파일을 다 지워야한다고 하셨다.
$ rm ._*
이렇게 만들어주었다.
결과가 잘 나온다
이제 첫 실습 데이터 준비
첫 번째 프로젝트에서 저장했었던 movie 데이터를 활용했다.
원래의 데이터를 한 번 더 to_parquet 하여 스파크가 읽을 수 있는 형태로 만들어줬다.
처음의 데이터는 특정 값이 null일 수 있는 파라미터에 대한 파티셔닝 설정이 제대로 이루어지지 않을 수 있다. 예를 들어, 일부 파라미터가 비어 있거나 잘못된 경우, 데이터가 저장될 때 null 또는 비어 있는 디렉토리 구조가 생길 수 있다. 이런 형태는 스파크가 읽을 수 없다고 한다.
import pandas as pd
df = pd.read_parquet('~/tmp/sparkdata')
df.to_parquet('~/tmp/sparkpartition', partition_cols=['load_dt','multiMovieYn', 'repNationCd'])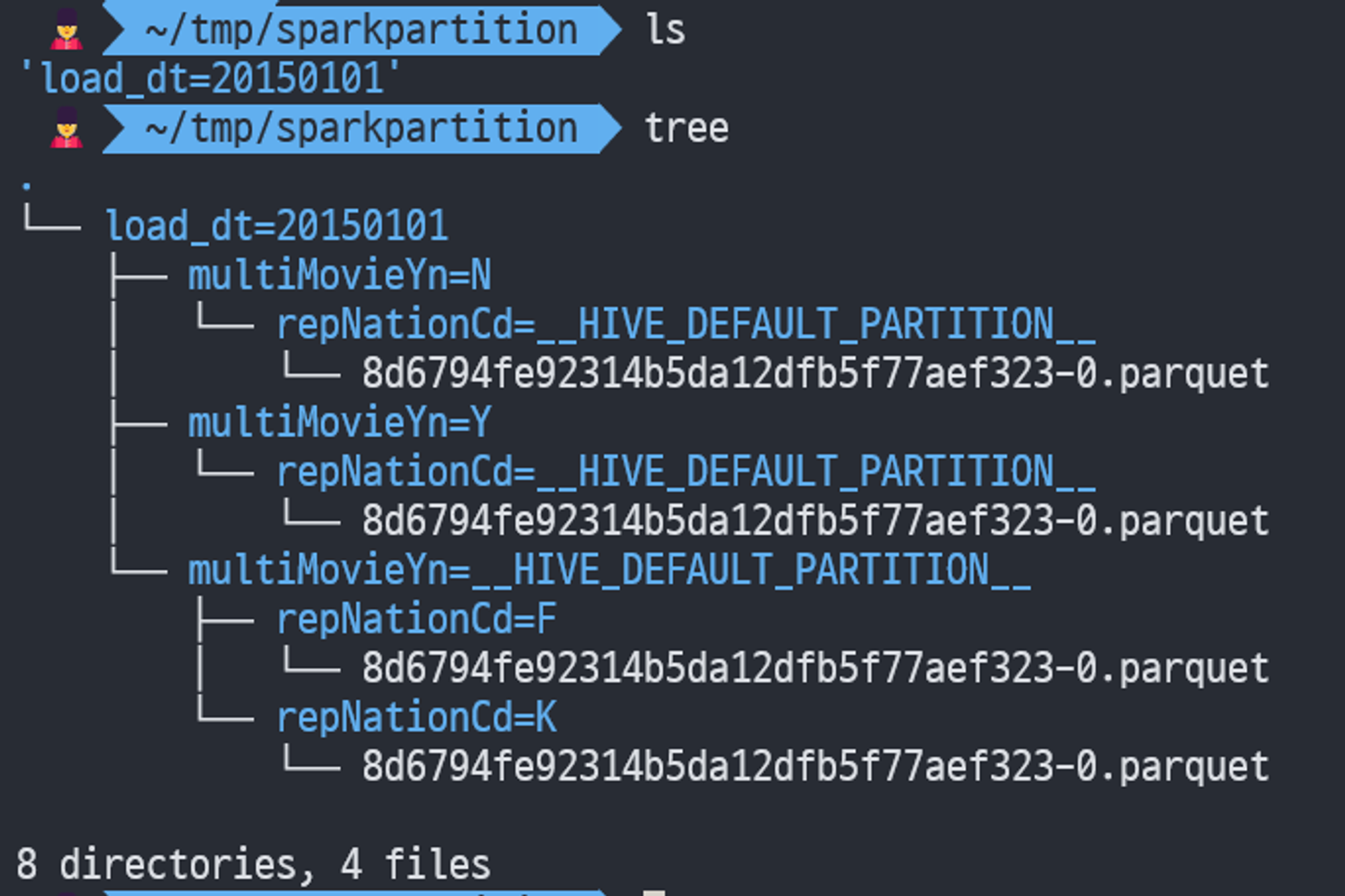
__HIVE_DEFAULT_PARTITION__은 일반적으로 "기본값"을 의미하며, 데이터가 지정된 다른 파티션이 없을 때 여기에 저장된다.
null 없이 파티셔닝이 명확하게 정의되어 있어서 Spark가 파티셔닝된 디렉토리 구조를 인식하고 데이터를 올바르게 읽을 수 있게 되었다.
[제플린에서 수행]
%spark.pyspark
df1 = spark.read.parquet("/home/sujin/tmp/sparkpartition")
%spark.pyspark
df1.show(10)
+----+----+---------+-------------+--------+----------------------------+----------+----------+----------+----------+-----------+-----------+-------+---------+----------+--------+-------+-------+--------+------------+-----------+
|rnum|rank|rankInten|rankOldAndNew| movieCd| movieNm| openDt| salesAmt|salesShare|salesInten|salesChange| salesAcc|audiCnt|audiInten|audiChange| audiAcc|scrnCnt|showCnt| load_dt|multiMovieYn|repNationCd|
+----+----+---------+-------------+--------+----------------------------+----------+----------+----------+----------+-----------+-----------+-------+---------+----------+--------+-------+-------+--------+------------+-----------+
| 1| 1| 1| OLD|20143642| 테이큰 3|2015-01-01|2644551100| 47.4|1640018100| 163.3| 3658460100| 321653| 177118| 122.5| 467280| 614| 2947|20150101| NULL| F|
| 2| 2| -1| OLD|20149859| 마다가스카의 펭귄|2014-12-31|1687516200| 30.3| 672528400| 66.3| 2736013000| 212779| 67641| 46.6| 361669| 594| 1846|20150101| NULL| F|
| 3| 3| 0| OLD|20140226| 호빗: 다섯 군대 전투|2014-12-17| 609678800| 10.9| 167361700| 37.8|22038162144| 69988| 8214| 13.3| 2579875| 346| 825|20150101| NULL| F|
| 4| 4| 0| OLD|20143344|눈의 여왕 2: 트롤의 마법거울|2014-12-24| 233190700| 4.2| 43780000| 23.1| 3856612400| 30978| 3375| 12.2| 529298| 246| 415|20150101| NULL| F|
| 5| 5| 0| OLD|20149120| 인터스텔라|2014-11-06| 192143100| 3.4| 70045000| 57.4|80863567400| 20636| 5353| 35|10125883| 97| 175|20150101| NULL| F|
| 6| 6| 1| OLD|20143602| 일곱난쟁이|2014-12-24| 65447200| 1.2| 8734100| 15.4| 1383364100| 9045| 749| 9| 193706| 90| 134|20150101| NULL| F|
| 7| 7| -1| OLD|20143422| 숲속으로|2014-12-24| 55772600| 1.0| -12642300| -18.5| 2465335488| 7195| -2604| -26.6| 324601| 113| 154|20150101| NULL| F|
| 8| 8| 19| OLD|20143045| 내일을 위한 시간|2015-01-01| 26098700| 0.5| 25508700| 4323.5| 50568800| 3035| 2955| 3693.8| 6034| 39| 89|20150101| NULL| F|
| 9| 9| -1| OLD|20141621| 마미|2014-12-18| 13704500| 0.2| -857000| -5.9| 288455700| 1533| -587| -27.7| 36655| 32| 47|20150101| NULL| F|
| 10| 10| -1| OLD|20143343| 무드 인디고|2014-12-11| 10800500| 0.2| 1382500| 14.7| 276643700| 1232| -104| -7.8| 34616| 26| 44|20150101| NULL| F|
+----+----+---------+-------------+--------+----------------------------+----------+----------+----------+----------+-----------+-----------+-------+---------+----------+--------+-------+-------+--------+------------+-----------+
only showing top 10 rows
%spark.pyspark
df2= df1['movieCd', 'multiMovieYn', 'repNationCd']
%spark.pyspark
df2.createOrReplaceTempView("movie_type")
%sql
SELECT * FROM movie_type
%spark.pyspark
df3 = spark.sql("SELECT * FROM movie_type WHERE multiMovieYn IS NULL")
df3.show(5)
+--------+------------+-----------+
| movieCd|multiMovieYn|repNationCd|
+--------+------------+-----------+
|20143642| NULL| F|
|20149859| NULL| F|
|20140226| NULL| F|
|20143344| NULL| F|
|20149120| NULL| F|
+--------+------------+-----------+
only showing top 5 rows
%spark.pyspark
df3.createOrReplaceTempView('multi_null')
%sql
select * from multi_null
[사진]
%spark.pyspark
df4=spark.sql("SELECT * FROM movie_type WHERE repNationCd IS NULL")
df4.show(5)
+--------+------------+-----------+
| movieCd|multiMovieYn|repNationCd|
+--------+------------+-----------+
|20141111| Y| NULL|
|20130574| Y| NULL|
|20143344| Y| NULL|
|20141614| Y| NULL|
|20143045| Y| NULL|
+--------+------------+-----------+
only showing top 5 rows
%sql
select * from nation_null
[사진]
%spark.pyspark
df = spark.sql("SELECT m.movieCd,n.multiMovieYn,m.repNationCd FROM multi_null m, nation_null n WHERE m.movieCd = n.movieCd")
df.show(10)
+--------+------------+-----------+
| movieCd|multiMovieYn|repNationCd|
+--------+------------+-----------+
|20143642| N| F|
|20149859| N| F|
|20140226| N| F|
|20143344| Y| F|
|20149120| N| F|
|20143602| N| F|
|20143422| N| F|
|20143045| Y| F|
|20141621| Y| F|
|20143343| Y| F|
+--------+------------+-----------+
only showing top 10 rows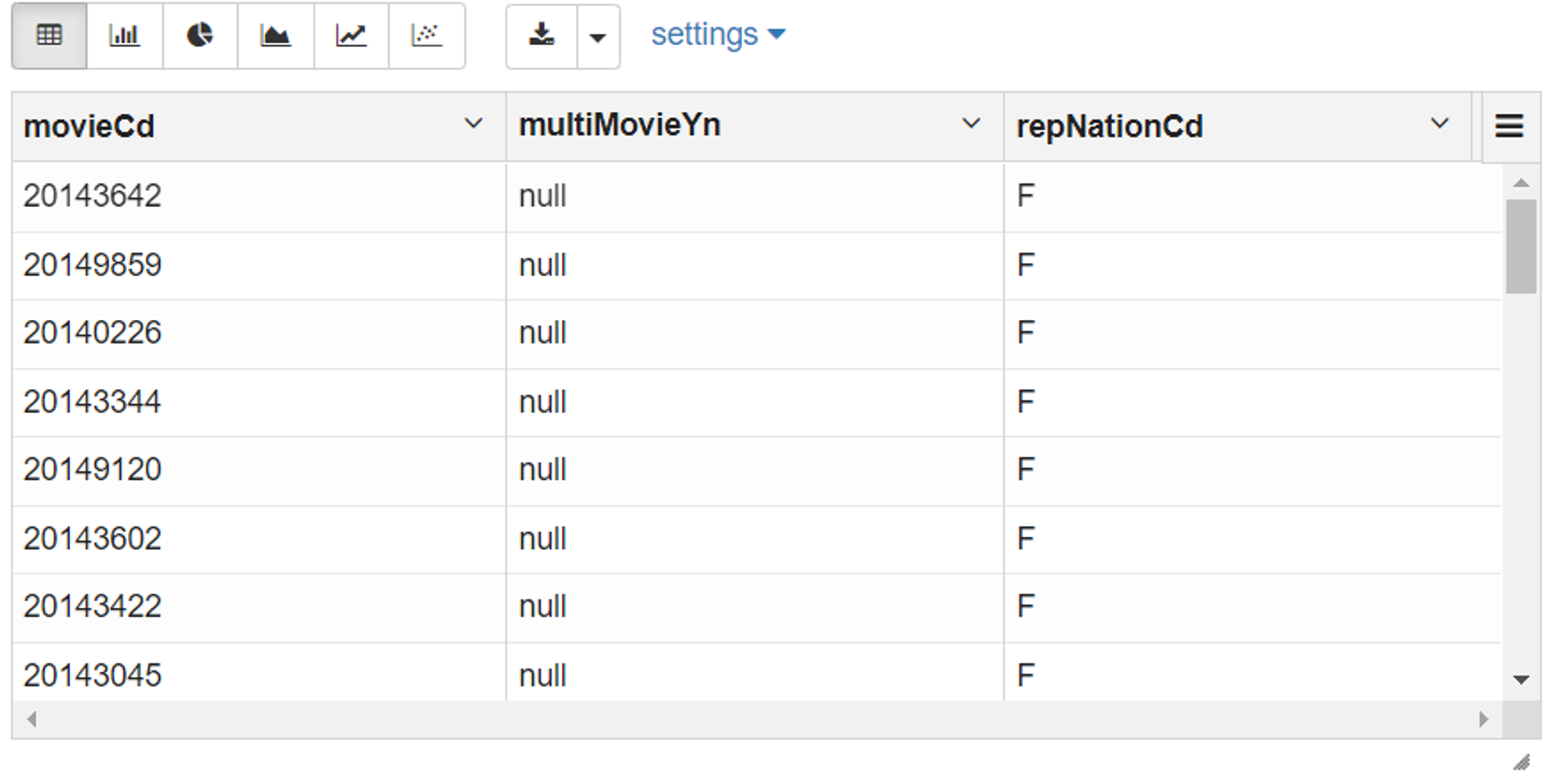
- spark.read.parquet - Parquet 파일 읽기: df1에 Parquet 형식 데이터 로드.
- df2.createOrReplaceTempView("movie_type") - 임시 뷰 생성: df2를 기반으로 SQL 쿼리에서 사용할 임시 뷰 movie_type 생성.
- %sql - SQL 쿼리 실행: movie_type 뷰에서 모든 데이터를 조회하여 결과를 반환.
%sql, %spark.pyspark 이런거 첨 사용해봐서 신기했다 ㅎㅎ
같은 코드를 리눅스 커맨드에서 pyspark를 실행시켜서 할 수도 있다.
$ cd ~/app/spark-3.5.1-bin-hadoop3
$ bin/pyspark
>>> df1=spark.read.parquet("/home/sujin/tmp/sparkpartition")
>>> df1.show()
| 1| 1| 1| OLD|20143642| 테이큰 3|2015-01-01|2644551100| 47.4|1640018100| 163.3| 3658460100| 321653| 177118| 122.5| 467280| 614| 2947|20150101| NULL| F|
| 2| 2| -1| OLD|20149859| 마다가스카의 펭귄|2014-12-31|1687516200| 30.3| 672528400| 66.3| 2736013000| 212779| 67641| 46.6| 361669| 594| 1846|20150101| NULL| F|
...
>>> df2= df1['movieCd', 'multiMovieYn', 'repNationCd']
>>> df2.show()
+--------+------------+-----------+
| movieCd|multiMovieYn|repNationCd|
+--------+------------+-----------+
|20143642| NULL| F|
|20149859| NULL| F|
|20140226| NULL| F|
|20143344| NULL| F|
|20149120| NULL| F|
|20143602| NULL| F|
|20143422| NULL| F|
|20143045| NULL| F|
|20141621| NULL| F|
|20143343| NULL| F|
|20137048| NULL| K|
|20141111| NULL| K|
|20149265| NULL| K|
|20130574| NULL| K|
|20147176| NULL| K|
|20141614| NULL| K|
|20143639| NULL| K|
|20143081| NULL| K|
|20141114| NULL| K|
|19900042| NULL| K|
+--------+------------+-----------+
>>> df2.createOrReplaceTempView("movie_type")
>>> df3=spark.sql("SELECT * FROM movie_type WHERE multiMovieYn IS NULL")
>>> df3.show()
+--------+------------+-----------+
| movieCd|multiMovieYn|repNationCd|
+--------+------------+-----------+
|20143642| NULL| F|
|20149859| NULL| F|
|20140226| NULL| F|
|20143344| NULL| F|
|20149120| NULL| F|
|20143602| NULL| F|
|20143422| NULL| F|
|20143045| NULL| F|
|20141621| NULL| F|
|20143343| NULL| F|
|20137048| NULL| K|
|20141111| NULL| K|
|20149265| NULL| K|
|20130574| NULL| K|
|20147176| NULL| K|
|20141614| NULL| K|
|20143639| NULL| K|
|20143081| NULL| K|
|20141114| NULL| K|
|19900042| NULL| K|
+--------+------------+-----------+
>>> df4=spark.sql("SELECT * FROM movie_type WHERE repNationCd IS NULL")
>>> df3.createOrReplaceTempView('multi_null')
>>> df4.createOrReplaceTempView('nation_null')
>>> df = spark.sql("SELECT m.movieCd,n.?,m.? FROM multi_null m, nation_null n WHERE m.movieCd = n.movieCd")
강사님이 퀴즈를 내셨다.
- 누락이 없는(양쪽에 하나라도 있는 영화는 누락이 없도록) 테이블의 ROW COUNT
- (1) 에 대한 중복을 제거한 ROW COUNT *중복을 제거가 무슨말인지 몰겟
- (2) 에 대해 multiMovieYn, repNationCd 모두 있는 ROW COUNT
- (2) 에 대해 multiMovieYn 가 없는(NULL) 인 ROW COUNT
- (2) 에 대해 repNationCd 가 없는(NULL) 인 ROW COUNT
나 sql 적당히 할 수 있다 생각했는데...... 어렵군
이거 할 때는 뭐 때문에 이 작업을 수행하는지 잘 이해를 못했었는데, 나중에 이해한바로는 한 테이블(meta_join) 안에 ['movieCd', 'multiMovieYn', 'repNationCd'] 이 컬럼들을 null 값 없이 조인을 통해 수행하려고 한거같다.
%spark.pyspark
df1=spark.read.parquet("/home/sujin/tmp/sparkpartition")
%spark.pyspark
df1.count()
# 40
%spark.pyspark
df2= df1['movieCd', 'multiMovieYn', 'repNationCd']
%spark.pyspark
df2.printSchema()
root
|-- movieCd: string (nullable = true)
|-- multiMovieYn: string (nullable = true)
|-- repNationCd: string (nullable = true)
%spark.pyspark
df2.createOrReplaceTempView("movie_type")
%sql
SELECT * FROM movie_type
%spark.pyspark
df3 = spark.sql("SELECT movieCd, repNationCd FROM movie_type WHERE multiMovieYn IS NULL")
df4 = spark.sql("SELECT movieCd, multiMovieYn FROM movie_type WHERE repNationCd IS NULL")
df3.createOrReplaceTempView("multi_null")
df4.createOrReplaceTempView("nation_null")
%sql
SELECT
*
FROM multi_null m FULL OUTER JOIN nation_null n
ON m.movieCd = n.movieCd
%sql
SELECT
COALESCE(m.movieCd, n.movieCd) AS movieCd,
multiMovieYn,
repNationCd
FROM multi_null m FULL OUTER JOIN nation_null n
ON m.movieCd = n.movieCd
%spark.pyspark
df_r = spark.sql("""SELECT
COALESCE(m.movieCd, n.movieCd) AS movieCd,
multiMovieYn,
repNationCd
FROM multi_null m FULL OUTER JOIN nation_null n
ON m.movieCd = n.movieCd""")
%spark.pyspark
df_r.count()
#22
%spark.pyspark
df_r.createOrReplaceTempView("meta_join")
%sql
SELECT * FROM meta_join
%sql
SELECT * FROM meta_join WHERE multiMovieYn IS NULL
%sql
SELECT * FROM meta_join WHERE repNationCd IS NULL
- spark 프로그램을 airflow에서 돌리려면?
https://spark.apache.org/docs/latest/quick-start.html#self-contained-applications
Quick Start - Spark 3.5.1 Documentation
Quick Start This tutorial provides a quick introduction to using Spark. We will first introduce the API through Spark’s interactive shell (in Python or Scala), then show how to write applications in Java, Scala, and Python. To follow along with this guid
spark.apache.org
또 공식문서 참조
사실 나는 아직 공식문서 보기 어렵다.
$ cd ~/code
$ mkdir spyspark
$ cd spyspark
$ vi SimpleApp.py
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("SimpleApp").getOrCreate()
logFile = "/home/sujin/app/spark-3.5.1-bin-hadoop3/README.md" # Should be some file on your system
logData = spark.read.text(logFile).cache()
numAs = logData.filter(logData.value.contains('a')).count()
numBs = logData.filter(logData.value.contains('b')).count()
print('*'*1000)
print("Lines with a: %i, lines with b: %i" % (numAs, numBs))
spark.stop()
$ $SPARK_HOME/bin/spark-submit SimpleApp.py- spark = SparkSession.builder.appName("SimpleApp").getOrCreate()
SparkSession 객체를 생성하여 Spark 애플리케이션을 시작한다. appName은 애플리케이션의 이름을 설정한다.
- SPARK_HOME/bin/spark-submit SimpleApp.py
작성한 애플리케이션을 실행하려면 spark-submit 명령어를 사용한다. spark-submit은 PySpark 애플리케이션을 클러스터에서 실행하는 데 사용된다.
[실습]

repartition
- code 를 참조하여 날짜 별로 진행(virtualenv operator + PDM 으로 만든 패키지)
- /home//data/movie/repartition/
join_df
- spark sql 을 활용(어제 작성한 제플린 코드) 하여 movie_join_df.py 을 $AIRFLOW_HOME/py 밑에 생성
- spark-submit 을 사용 airflow bash operator 를 이용
- 아래 pyspark 코드를 활용하여 HIVE 형식에 맞는 파티션 생성
df.write.partitionBy("load_dt", "multiMovieYn", "repNationCd").parquet("/home/<ID>/data/movie/hive/")agg
- sparksql 을 사용하여 일별 독립영화 여부, 해외영화 여부에 대하여 각각 합을 구하기(누적은 제외 일별관객수, 수익 ... )
- 위에서 구한 SUM 데이터를 "/home//data/movie/sum-multi", "/home//data/movie/sum-nation" 에 날짜를 파티션 하여 저장
제플린 대시보드 만들기
- 위에서 저장한 "/home//data/movie/sum-multi", "/home//data/movie/sum-nation" 데이터를 load 하여 차트 만들기
이 실습 나는 완성을 못했는데, 이번 주말에는 집에서 쓰는 맥에 지금까지 한 환경 설정들 하는데 잘 안돼서 시간을 다 써서 아직 회고에 올릴 수 없는 상태이다.... 다음 주 안에 무조건 완성한다 !!
🩷 좋았던 점
프로젝트 완성했다 ^___^
spark 배워보고 싶었는데 어떤 건지 조금 알게 되었다.
🥹 아쉬웠던 점
실습 완성을 못했다.
금요일에 ngnix, ngrinder에 대해 배웠는데, 이해가 안돼서 회고에도 못쓰겠다. 아직 뭐하는건지 잘 모르겠다.. 좀 더 배우고 이해하고 기록해야할 것 같다.
💪 이 상태에서 다음 일주일을 더 잘 보내려면 어떻게 해야 할까?
저번 주 실습 끝내기
금요일에 집중이 좀(많이) 깨졌는데 다시 집중해서 수업 잘 따라가기 ~.~
'playdata > weekly' 카테고리의 다른 글
| [플레이데이터 데이터 엔지니어링 캠프 32기] 7주차 회고 (1) | 2024.08.24 |
|---|---|
| [플레이데이터 데이터 엔지니어링 캠프 32기] 6주차 회고 (1) | 2024.08.18 |
| [플레이데이터 데이터 엔지니어링 캠프 32기] 4주차 회고 (1) | 2024.08.04 |
| [플레이데이터 데이터 엔지니어링 캠프 32기] 3주차 회고 (0) | 2024.07.30 |
| [플레이데이터 데이터 엔지니어링 캠프 32기] 2주차 회고 (1) | 2024.07.21 |