오늘의 팁
- 이력서에 너무 많은 스택은 못미더움ㅎ
- 필요에 따라 중복코드 있어도 된다. -> 배포관점으로 코드 작성해보기
저번 주 숙제 내용에서 딕셔너리 안 딕셔너리 안 딕셔너리 안 .. 이런 데이터를 이중 for 문 으로 처리했었다.

오늘은 이런 데이터를 flat하게 만드는 작업을 했다.
먼저 샘플데이터로 연습.
%spark.pyspark
data = [
("1", '{"name": "John Doe", "age": 30}'),
("2", '{"city": "New York", "country": "USA", "zipcode": "10001"}'),
("3", '{"product": "Laptop", "brand": "Dell", "specs": {"RAM": "16GB", "Storage": "512GB SSD"}}')
]
df = spark.createDataFrame(data, ["id", "json_string"])
z.show(df)data는 튜플 3개로 구성되어 있고, 각 튜플은 숫자가 문자열로 표현된 첫 번째 요소와, JSON 형식의 문자열로 이루어진 두 번째 요소가 있다. 특히 세번째 튜플은 중첩된 JSON 구조이다.
참고로 z.show(df)는 데이터프레임을 시각화하기 위해 사용되는 명령어이다.
%spark.pyspark
dynamic_schema = spark.read.json(
df.rdd.map(lambda row: row.json_string)
).schema
"""
StructType([
StructField('age', LongType(), True),
StructField('brand', StringType(), True),
StructField('city', StringType(), True),
StructField('country', StringType(), True),
StructField('name', StringType(), True),
StructField('product', StringType(), True),
StructField('specs', StructType([
StructField('RAM', StringType(), True),
StructField('Storage', StringType(), True)
]), True),
StructField('zipcode', StringType(), True)
])
"""
df(데이터프레임)를 RDD(Resilient Distributed Dataset)로 변환하는데, 각 행에서 JSON 문자열을 추출한 것을 읽어들여 스키마를 추출한다.
* RDD(Resilient Distributed Dataset)는 Apache Spark의 핵심 데이터 구조로, 대규모 데이터를 효율적으로 처리하기 위해 설계되었습니다. RDD는 Spark의 분산 데이터 처리의 기본 단위로, 분산 환경에서 데이터셋을 표현하고 처리할 수 있는 불변(immutable)하고 분산된 컬렉션입니다.
%spark.pyspark
from pyspark.sql.functions import from_json, col
df = df.withColumn('json_struct', from_json(col('json_string'), dynamic_schema))
z.show(df)*from_json() : JSON 문자열을 파싱하여 구조화된 데이터를 반환하는 데 사용됩니다.
json_string 컬럼의 JSON 문자열을 json_struct로 변환한다.
* 이 부분 이해가 안돼서 간단한 예제로 생각해보았다.
# 스키마 정의
schema = StructType([
StructField("name", StringType(), True),
StructField("age", IntegerType(), True)
])
# from_json 함수 사용
df_parsed = df.withColumn("parsed", from_json(col("json_string"), schema))
"""
{name, age}
+----------------------------+----------------+
|json_string |parsed |
+----------------------------+----------------+
|{"name": "John Doe", "age": 30} |{John Doe, 30}|
|{"name": "Jane Smith", "age": 25}|{Jane Smith, 25}|
+----------------------------+----------------+
"""parsed는 { name, age } 스키마를 사용하여 JSON 문자열을 파싱한다.
따라서 {John, 30 }
{Jane, 25 } 라는 결과를 얻은 것 이다.
json_struct는 { age brand. city country. name product specs zipcode } 스키마를 사용하여 JSON 문자열을 파싱한다.
따라서 id=1에서 [30 null null. null JD null null null ] 처럼 결과가 만들어지는 것 이다.
이제 df는 JSON 데이터를 구조화된 형태로 포함하는 새로운 컬럼(json_struct)을 갖게 되었다.
[실습] [AIRFLOW] movies-dynamic-json.py
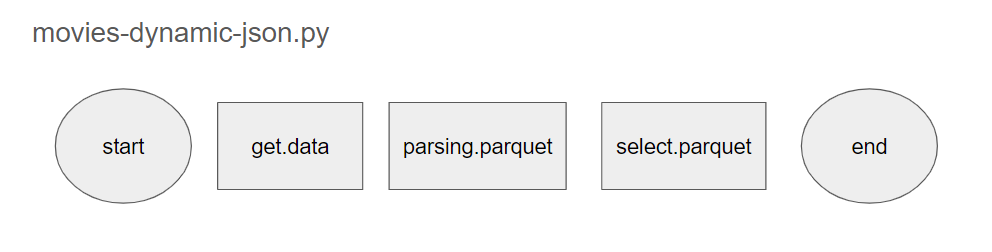
- 스케쥴은 DAG 설정에서 schedule="@once"
- MOVIE 목록은 page 1 ~ 10 page 까지만 API 호출하여 data 받고 ( task = get.data ) JSON 으로 저장
- pasing.prquet 에서는 위 샘플 코드 참조하여 펼쳐서 저장
- select.parquet 에서는 감독, 회사 별 영화 집계 groupby("감독") ...
schedule="@once",
start_date=datetime(2019, 1, 1),DAG 설정은 이렇게 해서 2019년 1월 1일 하루만 에어플로우가 돌아가도록 설정했다.
❗️ 그리고 실수했던 점은 DAG 파일 이름을 movies-dynamic-json.py 라고 설정한 것.
- 가 아닌 _ (언더바)를 사용하여 movies_dynamic_json.py 라고 해야한다.
1) get.data
import requests
import os
import json
import time
from tqdm import tqdm
API_KEY = os.getenv("MOVIE_API_KEY")
def save_json(data, file_path):
# 파일저장 경로 MKDIR
os.makedirs(os.path.dirname(file_path), exist_ok=True)
with open(file_path, 'w', encoding='utf-8') as f:
json.dump(data, f, indent=4, ensure_ascii=False)
def req(url):
r = requests.get(url)
j = r.json()
return j
def save_movies(year):
file_path = f'code/movdata/data/movies/year={year}/airflow_data.json'
# 위 경로가 있으면 API 호출을 멈추고 프로그램 종료
if os.path.exists(file_path):
print(f"데이터가 이미 존재합니다: {file_path}")
return True
url_base = f"https://kobis.or.kr/kobisopenapi/webservice/rest/movie/searchMovieList.json?key={API_KEY}&openStartDt={year}&openEndDt={year}"
all_data = []
for page in tqdm(range(1, 11)):
time.sleep(0.1)
r = req(url_base + f"&curPage={page}")
d = r['movieListResult']['movieList']
all_data.extend(d)
save_json(all_data, file_path)
return True이 부분은 저번 주 숙제 코드와 동일하다.
다른 점은 모든 페이지를 불러오지 않고 10페이지까지만 불러왔다는 점@@
def fun_getdata(dt):
print('*'*1000)
print(dt)
from movdata.get_data import save_movies
save_movies(dt)
get_data = PythonVirtualenvOperator(
task_id='get.data',
python_callable=fun_getdata,
requirements=["git+https://github.com/sooj1n/movdata.git@0.2.1/airflow"],
op_args=["{{ ds[:4] }}"],
system_site_packages=False
){[ ds[:4] }} 는 YYYY-MM-DD 포맷에서 YYYY만 슬라이싱하는 것 이다.
그래야 save_movies의 파라미터로 적절한 년도만 넘겨줄 수 있기 때문
[결과]

2) parsing.parquet
"""parsing.parquet.py"""
from pyspark.sql import SparkSession
import sys
APP_NAME = sys.argv[1]
YEAR = sys.argv[2]
spark = SparkSession.builder.appName(APP_NAME).getOrCreate()
# pyspark 에서 multiline(배열) 구조 데이터 읽기
jdf = spark.read.option("multiline","true").json(f"/home/sujin/code/movdata/data/movies/year={YEAR}/airflow_data.json")
# 펼치기
from pyspark.sql.functions import explode, col, size
edf = jdf.withColumn("company", explode("companys"))
# 또 펼치기
eedf = edf.withColumn("director", explode("directors"))
"""
eedf.select("movieCd", "company", "director").printSchema()
root
|-- movieCd: string (nullable = true)
|-- company: struct (nullable = true)
| |-- companyCd: string (nullable = true)
| |-- companyNm: string (nullable = true)
|-- director: struct (nullable = true)
| |-- peopleNm: string (nullable = true)
"""
# 또 또 펼치기
goal_df = eedf.select("movieCd","repGenreNm","repNationNm", "company.companyNm", "director.peopleNm")
goal_df.show()
goal_df.write.parquet(f"/home/sujin/code/movdata/data/movies/year={YEAR}/goal_data")
spark.stop()이 부분은 처음에 샘플데이터로 연습했던 부분이다.
multiline 옵션은 JSON 파일이 여러 줄에 걸쳐 작성된 경우 사용된다. 예를 들어, JSON 파일에서 하나의 JSON 객체가 여러 줄에 걸쳐 표현되어 있을 때, Spark는 기본적으로 이를 하나의 객체로 인식하지 못한다. 이 경우 multiline 옵션을 true로 설정하면 Spark는 여러 줄에 걸친 JSON 객체를 하나로 인식하고 처리한다.
예를 들어 이런 데이터에서 사용한다.
{
"name": "John Doe",
"age": 30,
"city": "New York"
}이렇게 읽은 JSON 데이터를 jdf에 저장하고, withColumn을 통해 flat한 형태로 만들어준다.
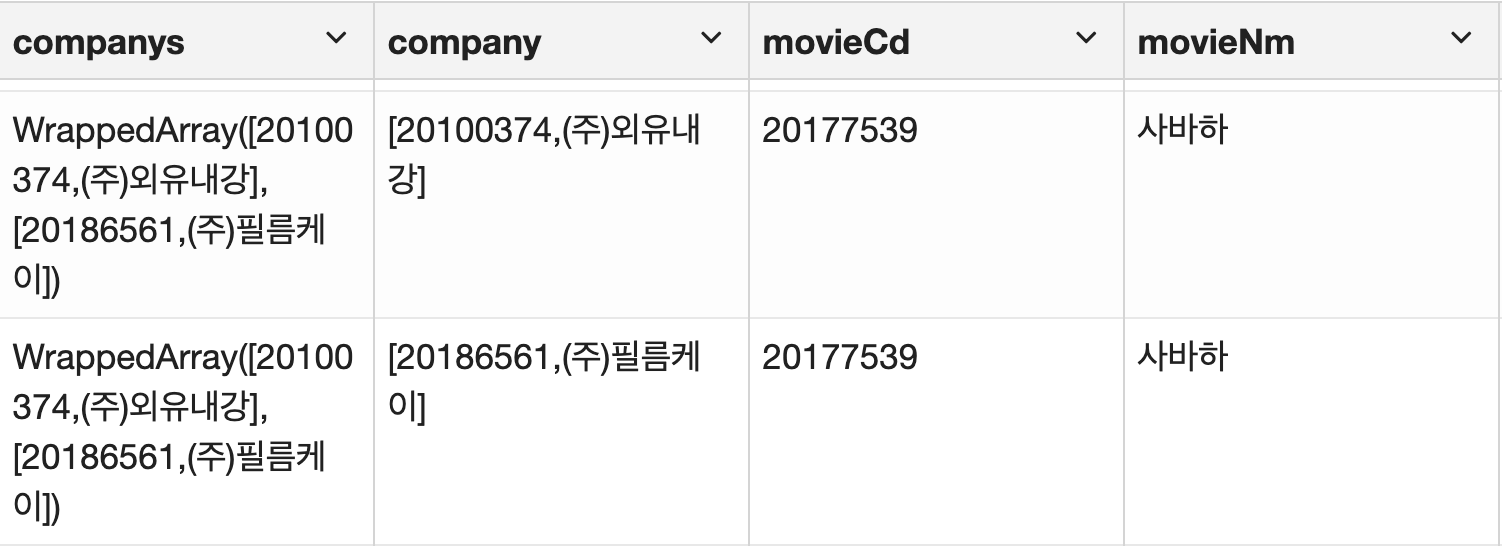
예시로, 사바하라는 영화는 외유내강, 필름케이 제작사가 참여했는데 (companys) 하나씩 지정된 company 컬럼을 확인할 수 있다.
같은 작업을 감독 데이터에 대해서 수행한 것이 eedf이다.
companys와 directors를 flat시킨 company와 director 또한 코드와 네임 배열로 구성되어 있다. 이것 또한 펼쳐주기 위해 eedf.select문을 실행했다.
❗️그리고 조금 헷갈렸던게, 이렇게 만든 데이터프레임을 다음 에어플로우 작업에서 사용하기 위해 어떻게 저장해야할지 몰랐다. 아직 parquet에 대한 이해가 살짝 부족했던 것 같다. parquet형식으로 저장하는것과 데이터프레임형식으로 저장하는 것은 같다고 생각하면 될 것 같다.
parsing_parquet = BashOperator(
task_id='parsing.parquet',
bash_command="""
$SPARK_HOME/bin/spark-submit /home/sujin/code/movdata/src/movdata/parsing_parquet.py "PARSING_TASK_APP" {{ ds[:4] }}
"""
)Spark 클러스터에서 parsing_parquet.py 파일을 실행하는 코드를 에어플로우로 구현한 부분이다.
3) select.parquet
"""select.parquet.py"""
from pyspark.sql.functions import count
from pyspark.sql import SparkSession
import sys
APP_NAME = sys.argv[1]
YEAR = sys.argv[2]
spark = SparkSession.builder.appName(APP_NAME).getOrCreate()
g = spark.read.parquet("/home/sujin/code/movdata/data/movies/year=2019/goal_data")
#g.show()
# 회사별 영화 개수
result = g.groupBy('companyNm').agg(count('movieCd').alias('movie_count'))
print("회사별 영화 개수")
result.show()
# 장르별 회사 개수
result = g.groupBy('repGenreNm').agg(count('companyNm').alias('company_count'))
print('장르별 회사 개수')
result.show()
# 감독별 영화 수
result = g.groupBy('peopleNm').agg(count('movieCd').alias('movie_cnt'))
print('감독별 영화 수')
result.show()
spark.stop()나는 회사별 영화 수, 장르별 회사 개수, 감독별 영화 수를 추출(?)계산(?)해보았다.
select_parquet = BashOperator(
task_id='select.parquet',
bash_command="""
$SPARK_HOME/bin/spark-submit /home/sujin/code/movdata/src/movdata/select_parquet.py "SELECT_TASK_APP" {{ ds[:4] }}
"""
)
-회사 별 영화 수

-장르 별 회사 수

-감독 별 영화 수

- Explode vs explode_outer
explode는 null 이거나 빈 배열인 경우 ROW가 제외된다.
explode_outer를 사용하여 보존하기
# 수정
# 펼치기
from pyspark.sql.functions import explode_outer, col, size
edf = jdf.withColumn("company", explode_outer("companys"))
# 또 펼치기
eedf = edf.withColumn("director", explode_outer("directors"))

- Dynamic Form -> 현업에서 많이 사용했다고 하셨다.
사용자가 입력한 값에 따라 인터페이스가 실시간으로 변경되는 양식을 제공하는 기능.
[사용예시]
SELECT directorNm, COUNT(*) AS cnt
FROM movdir
WHERE directorNm = '${directorName}' -- 사용자가 입력한 이름을 쿼리에 적용
GROUP BY directorNm
ORDER BY cnt DESC
LIMIT 10%sql
SELECT directorNm, COUNT(*) AS cnt FROM movdir
GROUP BY directorNm
HAVING cnt > ${minCount} -- 사용자가 입력한 숫자 값을 쿼리에 적용
ORDER BY cnt DESC
LIMIT 10
[SPARK]
# 1. 텍스트 입력 예제
%spark.pyspark
print("Hello" + z.textbox("name", "Michelle"))
print("Hello" + z.input("name"))
# 2. 체크박스
%spark.pyspark
# 옵션 정의
options = [("apple", "Apple"), ("banana", "Banana"), ("orange", "Orange")]
# 사용자의 체크박스 선택 값을 가져오기
selected_fruits = z.checkbox("fruit", options)
# 체크된 옵션의 레이블만 추출하여 리스트로 변환
selected_fruit_labels = [label for value, label in options if value in selected_fruits]
# 결과를 문자열로 결합
result = "Hello " + " and ".join(selected_fruit_labels)
print(result)
#3. select 박스
%spark.pyspark
print("Hello "+z.select("day", (("1","mon"),
("2","tue"),
("3","wed"),
("4","thurs"),
("5","fri"),
("6","sat"),
("7","sun"))))
- Kafka
Apache Kafka는 대용량의 실시간 데이터 스트림을 처리하고 관리하기 위해 설계된 분산형 이벤트 스트리밍 플랫폼입니다. LinkedIn에서 개발되었으며, 이후 Apache Software Foundation의 오픈 소스 프로젝트로 관리되고 있습니다.
-설치
$ cd tmp/down
$ wget https://dlcdn.apache.org/kafka/3.8.0/kafka_2.13-3.8.0.tgz
$ tar -xvf kafka_2.13-3.8.0.tgz
$ mv kafka_2.13-3.8.0 ~/app
$ vi ~/.zshrc
export KAFKA_HOME=/home/sujin/app/kafka_2.13-3.8.0
-실행
$ bin/zookeeper-server-start.sh config/zookeeper.properties
$ bin/kafka-server-start.sh config/server.properties
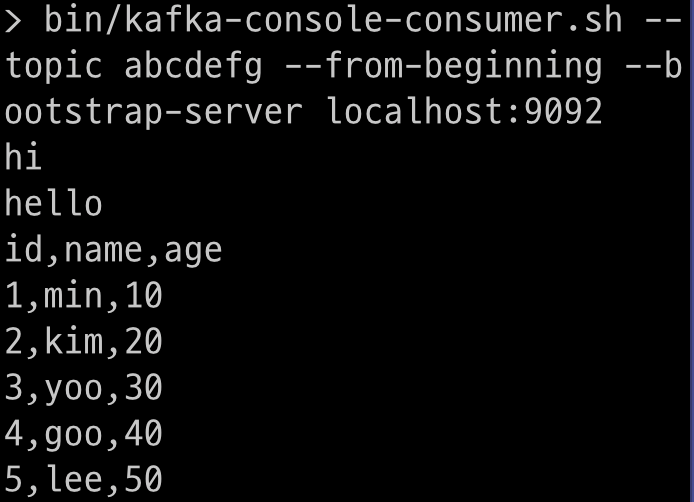
$ bin/kafka-topics.sh --create --topic abcdefg --bootstrap-server localhost:9092
$ bin/kafka-console-producer.sh --topic abcdefg --bootstrap-server localhost:9092
>hi
>hello여기 입력하는 내용이
bin/kafka-console-consumer.sh --topic abcdefg --from-beginning --bootstrap-server localhost:9092
hi
hello여기에서 출력된다. 신기 ㅎ
[실행파일]
$ mkdir ~/code/kafka-producer
$ vi ~/code/kafka-producer/abcdefg.csv
id,name,age
1,min,10
2,kim,20
3,yoo,30
4,goo,40
5,lee,50
$ vi ~/code/kafka-producer/abcdefg.sh
#!/bin/bash
echo "### KAFKA Producer START ###"
cat abcdefg.csv | while read line; do
echo "$line"
sleep 1
done | $KAFKA_HOME/bin/kafka-console-producer.sh --topic abcdefg --bootstrap-server localhost:9092
echo "### KAFKA Producer END ###"$ bash produce_abcdefg.sh실행하면 console-consumer에 csv 파일 내용이 출력된다.
- Kafka Python
- Apache Kafka라는 분산 스트리밍 플랫폼을 Python 언어로 사용하기 위한 라이브러리
- 파이썬 3.8까지 지원한다.
$ pyenv install 3.8.19- 카프카는 2.4.1 버전을 다운받았다.
$ wget https://archive.apache.org/dist/kafka/2.4.1/kafka_2.12-2.4.1.tgz
# producer.py
from kafka import KafkaProducer
import time
import json
from tqdm import tqdm
pro = KafkaProducer(
bootstrap_servers=['localhost:9092'],
value_serializer=lambda x: json.dumps(x).encode('utf-8')
)
start = time.time()
for i in tqdm(range(10)):
data = {'str': 'value' + str(i)}
pro.send('topic1', value=data)
pro.flush()
time.sleep(1)
end = time.time()
print("[DONE]:", end - start)1) KafkaProducer 초기화
bootstrap_servers : Kafka 브로커의 주소 설정
value_serializer : 메시지를 JSON 형식으로 직렬화하여 UTF-8로 인코딩
2) 데이터 전송
for 루프를 통해 10개의 메시지를 생성하여 topic1에 전송한다. 이때, pro.send()로 데이터를 전송한 후 pro.flush()로 버퍼를 비워 메시지가 즉시 전송되도록 함.
3) 시간 측정 : 메시지를 전송하는 데 걸린 시간을 측정하여 출력한다.
from kafka import KafkaConsumer, TopicPartition
from json import loads
import os
OFFSET_FILE = 'consumer_offset.txt'
def save_offset(offset):
with open(OFFSET_FILE, 'w') as f:
f.write(str(offset))
def read_offset():
if os.path.exists(OFFSET_FILE):
with open(OFFSET_FILE, 'r') as f:
return int(f.read().strip())
return None
saved_offset = read_offset()
consumer = KafkaConsumer(
#'topic1',
bootstrap_servers=['localhost:9092'],
value_deserializer=lambda x: loads(x.decode('utf-8')),
consumer_timeout_ms=5000,
#auto_offset_reset="earliest" if saved_offset is None else 'none',
group_id="fbi", #같은그룹으로 묶고 알려준다.
enable_auto_commit=False
)
#consumer_timeout_ms=5000 // 타임아웃 5초 후
#auto_offset_reset=' ' // earliest 이전기록 전부 출력 후 실행, latest 요청 한번만 실행
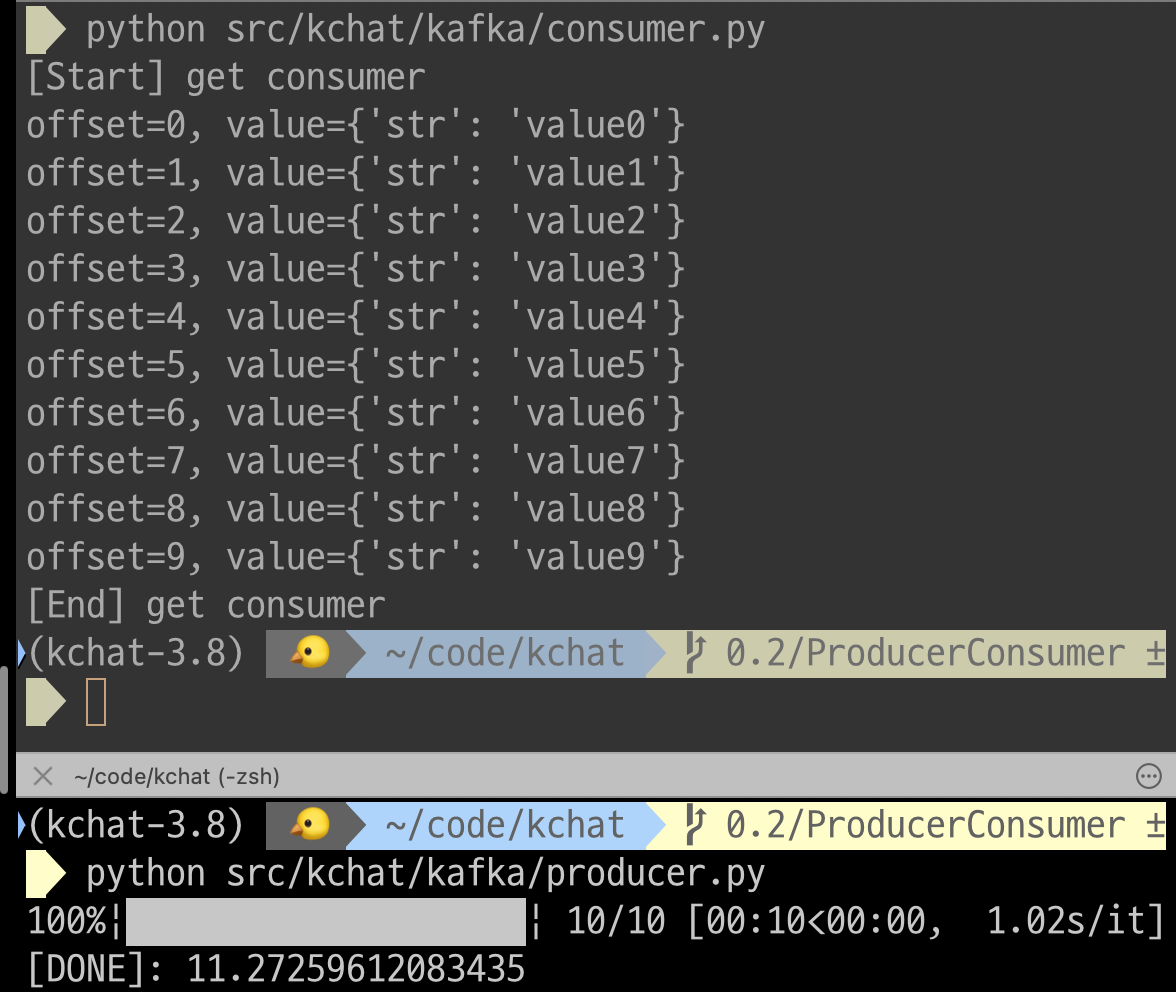
print("[Start] get consumer")
p = TopicPartition('topic1', 0) # 0 은 파티션 넘버
consumer.assign([p])
if saved_offset is not None:
consumer.seek(p, saved_offset)
else:
consumer.seek_to_beginning(p)
for msg in consumer:
print(f"offset={msg.offset}, value={msg.value}")"
save_offset(msg.offset + 1)
#if msg.value['str'] == 'value9':
# print("Exit message received, closing consumer.")
# break # 루프 탈출
print("[End] get consumer")
1) 오프셋(메시지를 읽고있는 위치) 관리
save_offset: consumer_offset.txt 파일에 오프셋을 저장
read_offset: 오프셋 읽어오기
만약 저장된 오프셋이 존재하면 그 위치부터 메시지를 읽고, 그렇지 않으면 처음부터 읽는다.
파일이 존재하지 않으면 None을 반환.
2) KafkaConsumer 초기화
bootstrap_servers : Kafka 브로커의 주소를 설정
value_deserializer : 메시지를 UTF-8로 디코딩하여 JSON 형식으로 역직렬화
group_id : 지정된 소비자 그룹에 속하게 한다.
consumer_timeout_ms : 5초(5000) 동안 메시지가 없으면 for 루프를 종료하도록 설정
auto_offset_reset : 저장된 오프셋이 없으면 earliest(가장 처음)부터 메시지를 읽음. cf) Latest(가장 마지막)
enable_auto_commit=False: 자동으로 오프셋을 커밋하지 않도록 설정하고, 수동으로 오프셋을 관리합니다.
3) TopicPartition 할당
TopicPartition('topic1', 0): topic1의 파티션 0을 지정. 파티션 번호는 Kafka의 메시지 분산 처리 시 사용된다.
consumer.assign(): 소비자가 해당 파티션에서만 메시지를 수신하도록 할당.
4) 오프셋 위치 설정
만약 저장된 오프셋이 있다면(saved_offset is not None), 해당 위치에서부터 메시지 소비를 시작한다.
저장된 오프셋이 없다면(else), 해당 파티션의 처음부터 메시지를 읽는다.(seek_to_beginning(p)).
5) 메시지 처리
Kafka로부터 메시지를 소비할 때마다 메시지의 오프셋과 값을 출력하고, 다음 번 실행 시 이 메시지를 중복 처리하지 않도록 오프셋을 save_offset(msg.offset + 1)로 저장한다.
[결과]
producer에서 메시지가 생성될 때 마다 consumer에 출력된다.
- 메시지를 직접 입력하는 예제
from kafka import KafkaProducer
import time
import json
p = KafkaProducer(
#TODO
bootstrap_servers=['localhost:9092'],
value_serializer=lambda x: json.dumps(x).encode('utf-8')
)
print("채팅 프로그램 - 메시지 발신자")
print("메시지를 입력하세요. (종료시 'exit' 입력")
while True:
msg = input("YOU: ")
if msg.lower() == 'exit':
break
data = {'message':msg, 'time': time.time()}
# TODO 보내기
p.send('chat', value=data)
print("채팅 종료")from kafka import KafkaConsumer
from json import loads
consumer = KafkaConsumer(
'chat',
bootstrap_servers=['localhost:9092'],
auto_offset_reset='earliest',
enable_auto_commit=True,
group_id='chat-group',
value_deserializer=lambda x: loads(x.decode('utf-8'))
)
print("채팅프로그램 - 메시지 수신")
print("메시지 대기 중 ...")
try:
for m in consumer:
#print(f"[FRIEND] {m['message']}")
#print(f"[FRIEND] value={m.message}")
print(f"[FRIEND] {m.value['message']}")
except KeyboardInterrupt:
print("채팅 종료")
finally:
consumer.close(){m.value['message']} 이 부분이 좀 헷갈렸다.
m 자체는
ConsumerRecord(topic='chat', partition=0, offset=7, timestamp=1724246882340, timestamp_type=0, key=None, value={'message': '안녕요', 'time': 1724246882.338059}, headers=[], checksum=None, serialized_key_size=-1, serialized_value_size=60, serialized_header_size=-1)
===> 이런 형태이기 때문에 m에서 value의 message만 꺼내왔다.
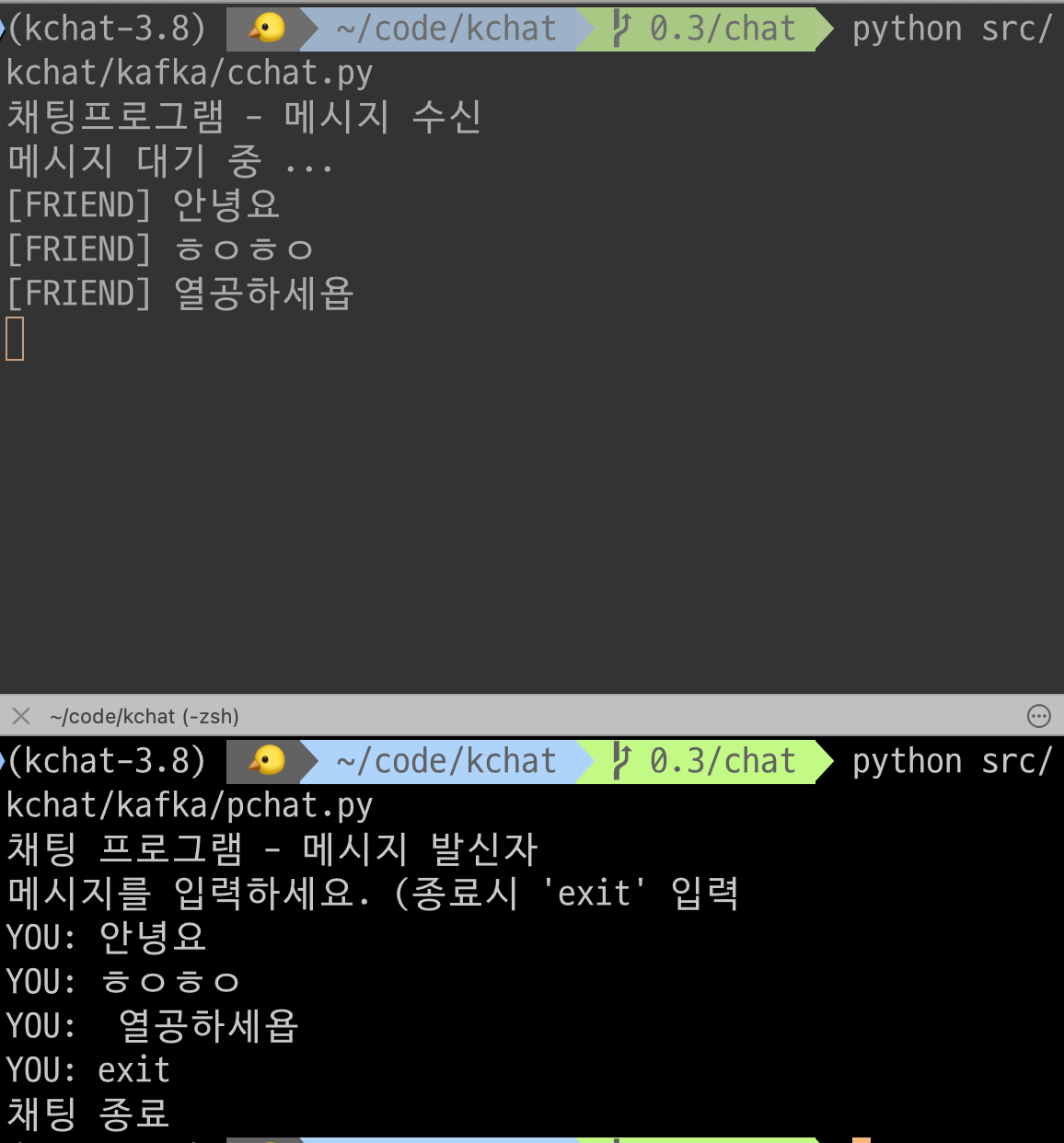
pcaht에서 입력한 메시지가 chat에서 출력된다 !!또 신기..
---
오늘은 서버에 접속해서 채팅을 주고받을 수 있는 기능을 구현했다.
일단은 이렇게 서버에 접속했다.
$ ssh -i samdulko.pem ubuntu@<비밀>
하나의 파이썬 코드에 producer와 consumer를 모두 작성해서 메시지를 주고 받을 수 있도록 했다.
스레드를 통해 두 기능이 동시에 수행될 수 있다.
메시지를 생성하면 서버로 보내지고 서버의 메시지를 받아오는 거 인듯(?)
from kafka import KafkaConsumer
from kafka import KafkaProducer
import json
import time
import threading
from json import loads
p = KafkaProducer(
bootstrap_servers=['3.38.102.55:9092'],
#bootstrap_servers=['localhost:9092'],
value_serializer=lambda x: json.dumps(x).encode('utf-8')
)
c = KafkaConsumer(
'chat',
bootstrap_servers=['3.38.102.55:9092'],
#bootstrap_servers=['localhost:9092'],
auto_offset_reset='latest',
#enable_auto_commit=True,
#group_id='chat-group',
value_deserializer=lambda x: loads(x.decode('utf-8'))
)
def producer(username):
print("메시지를 입력하세요. (종료시 'exit' 입력")
while True:
msg = input(f"{username}: ")
if msg.lower() == 'exit':
break
data = {'username': username, 'message':msg, 'time': time.time()}
p.send('chat', value=data)
print("채팅 종료")
def consumer():
print("채팅프로그램 - 메시지 수신")
print("메시지 대기 중 ...")
try:
for m in c:
print(f"[{m.value['time']}] {m.value['username']} {m.value['message']}")
#print(m)
except KeyboardInterrupt:
print("채팅 종료")
finally:
c.close()
if __name__ == "__main__":
print("채팅 프로그램 - 메시지 발신 및 수신")
username = input("사용할 이름을 입력하세요 : ")
consumer_thread = threading.Thread(target=consumer)
producer_thread = threading.Thread(target=producer, args=(username,))
consumer_thread.start()
producer_thread.start()
그리고 if __name__ == "__main__"은 어제 처음 써 봤다.
- __name__ 변수:
- Python에서 각 스크립트 파일에는 __name__이라는 특별한 변수가 있습니다.
- 스크립트를 직접 실행할 때는 __name__의 값이 "__main__"이 됩니다.
- 반면, 다른 스크립트에서 모듈로 임포트할 경우, __name__은 해당 모듈의 이름이 됩니다.
- if __name__ == "__main__":의 역할:
- 이 조건문은 해당 스크립트가 직접 실행된 경우에만 특정 코드 블록이 실행되도록 합니다.
- 반대로, 이 스크립트가 다른 모듈에 임포트되었을 때는 조건문 안의 코드는 실행되지 않습니다.
그렇다고함.. 사용자 이름을 받는 부분에서 사용했다.
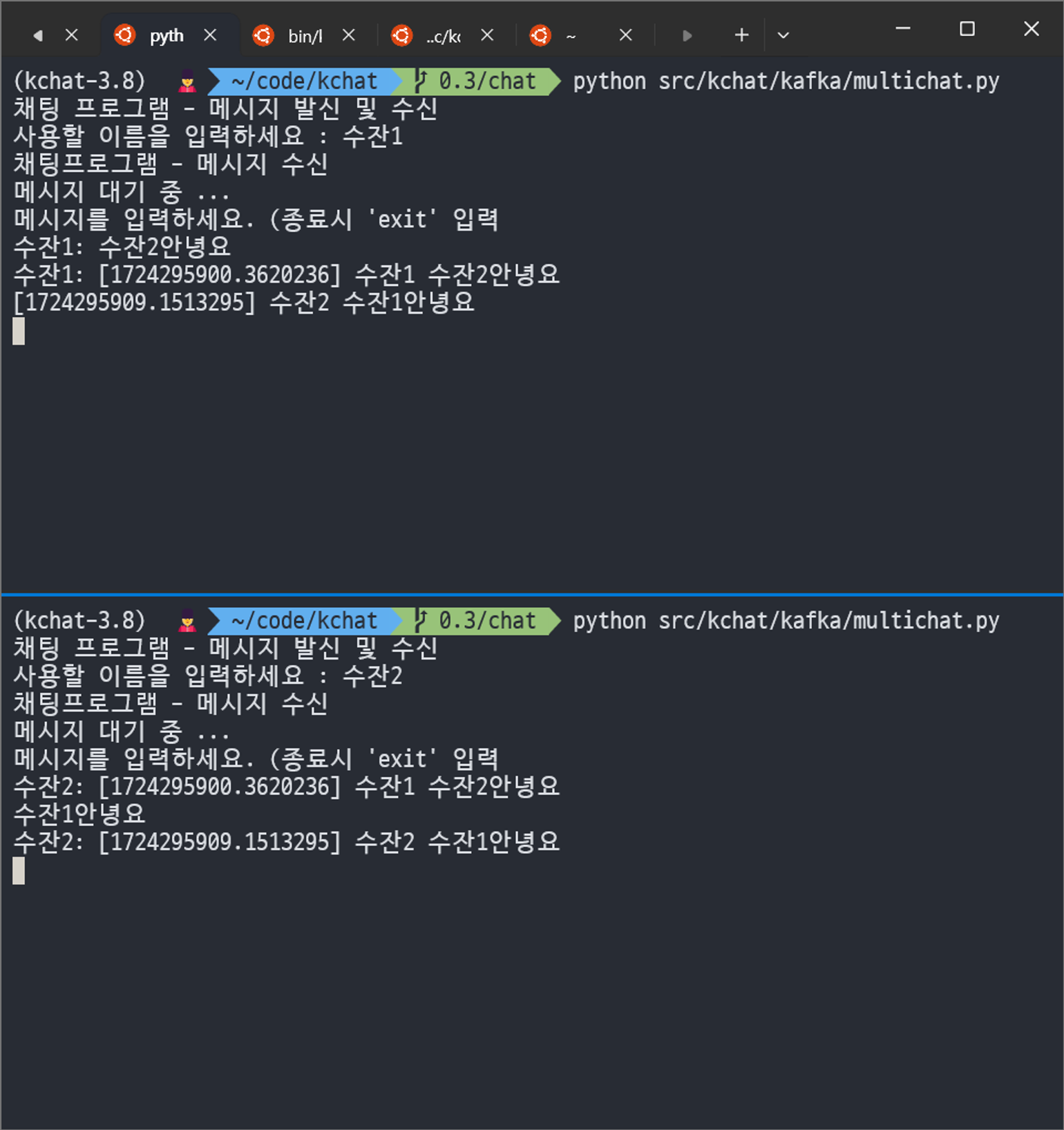
이렇게 창 2개에서 대화할 수 있다.
- docker
일단 알려주시는대로 뭔가를 하긴 했는데, 뭔지를 모르겠어서 개념을 찾아보았다.
Docker는 애플리케이션을 컨테이너(Container)로 가상화하여 실행 환경을 제공하는 플랫폼입니다. 컨테이너는 애플리케이션과 그 실행에 필요한 라이브러리, 설정 파일 등을 패키지화하여 어디서든 동일한 환경에서 실행될 수 있도록 하는 기술입니다. 이를 통해 개발자는 로컬 환경에서 개발한 애플리케이션을 별다른 환경 설정 없이 배포 서버에서 그대로 실행할 수 있습니다.
[설치]
오늘은 맥 버전으로 기록해보겠닷
$ brew install --cask docker
$ docker --version
Docker version 27.1.1, build 6312585이후 설치된 도커 애플리케이션에 접속해서 로그인을 했다.
$ docker login
Authenticating with existing credentials...
Login Succeeded
그리고 docker-compose.yml 파일을 생성했다.
도커에서 컴포즈란?
-
Docker Compose는 다중 컨테이너 Docker 애플리케이션을 정의하고 실행할 수 있게 해주는 도구입니다. Docker는 개별 컨테이너로 애플리케이션의 각 구성 요소(예: 웹 서버, 데이터베이스, 캐시 서버 등)를 분리하여 실행할 수 있게 해주는데, Docker Compose는 이 여러 컨테이너를 쉽게 관리하고 조정할 수 있게 해줍니다.
$ cd tmp/docker
$ vi docker-compose.yml
services:
controller-1:
image: apache/kafka:latest
container_name: controller-1
environment:
KAFKA_NODE_ID: 1
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@controller-1:9093,2@controller-2:9093,3@controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
controller-2:
image: apache/kafka:latest
container_name: controller-2
environment:
KAFKA_NODE_ID: 2
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@controller-1:9093,2@controller-2:9093,3@controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
controller-3:
image: apache/kafka:latest
container_name: controller-3
environment:
KAFKA_NODE_ID: 3
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@controller-1:9093,2@controller-2:9093,3@controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
broker-1:
image: apache/kafka:latest
container_name: broker-1
ports:
- 29092:9092
environment:
KAFKA_NODE_ID: 4
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: 'PLAINTEXT://:19092,PLAINTEXT_HOST://:9092'
KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://broker-1:19092,PLAINTEXT_HOST://localhost:29092'
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@controller-1:9093,2@controller-2:9093,3@controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
depends_on:
- controller-1
- controller-2
- controller-3
broker-2:
image: apache/kafka:latest
container_name: broker-2
ports:
- 39092:9092
environment:
KAFKA_NODE_ID: 5
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: 'PLAINTEXT://:19092,PLAINTEXT_HOST://:9092'
KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://broker-2:19092,PLAINTEXT_HOST://localhost:39092'
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@controller-1:9093,2@controller-2:9093,3@controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
depends_on:
- controller-1
- controller-2
- controller-3
broker-3:
image: apache/kafka:latest
container_name: broker-3
ports:
- 49092:9092
environment:
KAFKA_NODE_ID: 6
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: 'PLAINTEXT://:19092,PLAINTEXT_HOST://:9092'
KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://broker-3:19092,PLAINTEXT_HOST://localhost:49092'
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@controller-1:9093,2@controller-2:9093,3@controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
depends_on:
- controller-1
- controller-2
- controller-3Kafka 컨트롤러 3개와 브로커 3개를 각각의 Docker 컨테이너에서 실행한다..
$ sudo docker compose up -d
$ sudo docker compose ps
$ sudo docker ps
$ sudo docker compose down
$ sudo docker compose stop
$ sudo docker compose start이렇게 도커 컴포즈를 실행하고 중지시킬 수 있는데 일단 뭔지 감이 잘 안잡히기 때문에 나중에 이걸 사용해서 뭔갈 더 한다면 이해를 잘 해서 다시 기록하겠다 ㅎ_ㅎ
🩷 좋았던 점
강사님이 실습 내주시는거 한 번에 완성한 적이 없었는데 처음 완성해봤다.
카프카를 통해 채팅 기능을 만들어봤는데, 주제가 재밌었다.
🥹 아쉬웠던 점
도커 이해xxxxxxxxx
뭔지알겠는데뭔지모르겠고뭔지알겠는데모르겠고.......
도커를 사용한 다른 실습을 해보고싶다
💪 이 상태에서 다음 일주일을 더 잘 보내려면 어떻게 해야 할까?
이번 금요일 오후부터 담주 수욜까지 진행될 팀플을 시작했다!! 팀원분들이 다 너무 똑똑하시고 멋있어서 민폐끼치지 않게 주말에 열공해서 갈 것임~!

'playdata > weekly' 카테고리의 다른 글
| [플레이데이터 데이터 엔지니어링 캠프 32기] 9주차 회고 (2) | 2024.09.09 |
|---|---|
| [플레이데이터 데이터 엔지니어링 캠프 32기] 8주차 회고 (3) | 2024.09.01 |
| [플레이데이터 데이터 엔지니어링 캠프 32기] 6주차 회고 (1) | 2024.08.18 |
| [플레이데이터 데이터 엔지니어링 캠프 32기] 5주차 회고 (1) | 2024.08.12 |
| [플레이데이터 데이터 엔지니어링 캠프 32기] 4주차 회고 (1) | 2024.08.04 |