
1. pip install을 나의 git url로 변경한다.
기존의 절대 경로는 문제가 될 수도 있다. (사용자의 로컬에는 같은 경로가 아닐 수도 있기 때문에)
도커파일을 수정해준다.
#RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
RUN pip install git+https://<MY_PIP_GITHUB_URL>
이미지 파일을 빌드하고 실행시킨 후, 컨테이너에 접속하여 pip list를 수행했는데, fishmlserv가 0.7.0 버전이었다.
$ docker build -t fishmlserv:0.7.6 .
$ docker run -d -p 7799:8080 --name fml076 fishmlserv:0.7.6
$ docker exec -it fml070 bash
root@6336c9682ed3:/code# pip list
fishmlserv 0.7.0
.
.
.
Dockerfile에 변화가 없으면 어짜피 같은 버전이라고 생각하고 갱신하지 않는 문제였다.
--no-cache-dir 옵션으로 이전에 캐시된 결과를 사용하지 않고 내용에 변화가 없어도 갱신하도록 했다.
$ cat Dockerfile
RUN pip install --no-cache-dir --upgrade git+https://github.com/sooj1n/fishmlserv.git@0.7/MANIFEST$ docker build --no-cache -t fishmlserv:0.7.10 .
2. model.pkl을 위 Install에서 포함되도록 한다.
로컬에서 실행할 땐 model.pkl이 없다. pip install은 확장자가 py 인 것은 이동하지만 아닌 것(pkl 등)은 이동 안시키기 때문이다.
pip install 될 때 model.pkl도 같이 이동시키도록 한다.
$ cat MANIFEST.in
recursive-include src *.pkl
3. model.pkl이 설치된 위치를 찾아서 fastapi에서 이용하도록 수정
$ cat manager.py
import os
import sys
import pickle
def get_model_path():
# 이 함수 파일의 절대 경로를 받아온다.
my_path = __file__
dir_name = os.path.dirname(my_path)
# 절대 경로를 이용해 model.pkl의 경로를 조합
model_path = os.path.join(dir_name, "model.pkl")
# 조합된 경로를 리턴 - 끝
return model_path
# fastapi mian.py에서 아래와 같이 사용
# from fishmlserv.model.manager import get_model_path$ cat src/fishmlserv/main.py
from fishmlserv.model.manager import get_model_path
@app.get("/fish")
def fish(length: float, weight:float):
"""
물고기의 종류 판별기
Args:
length (float): 물고기 길이(cm)
weight (float): 물고기 무게(g)
Returns:
dict: 물고기 종류를 담은 딕셔너리
"""
### 모델 불러오기
with open(get_model_path(), "rb") as f:
fish_model = pickle.load(f)
prediction = fish_model.predict([[length, weight]])
if prediction[0] == 1:
fish_class = "도미"
else:
fish_class = "빙어"
return {
"prediction": fish_class,
"length": length,
"weight": weight
}
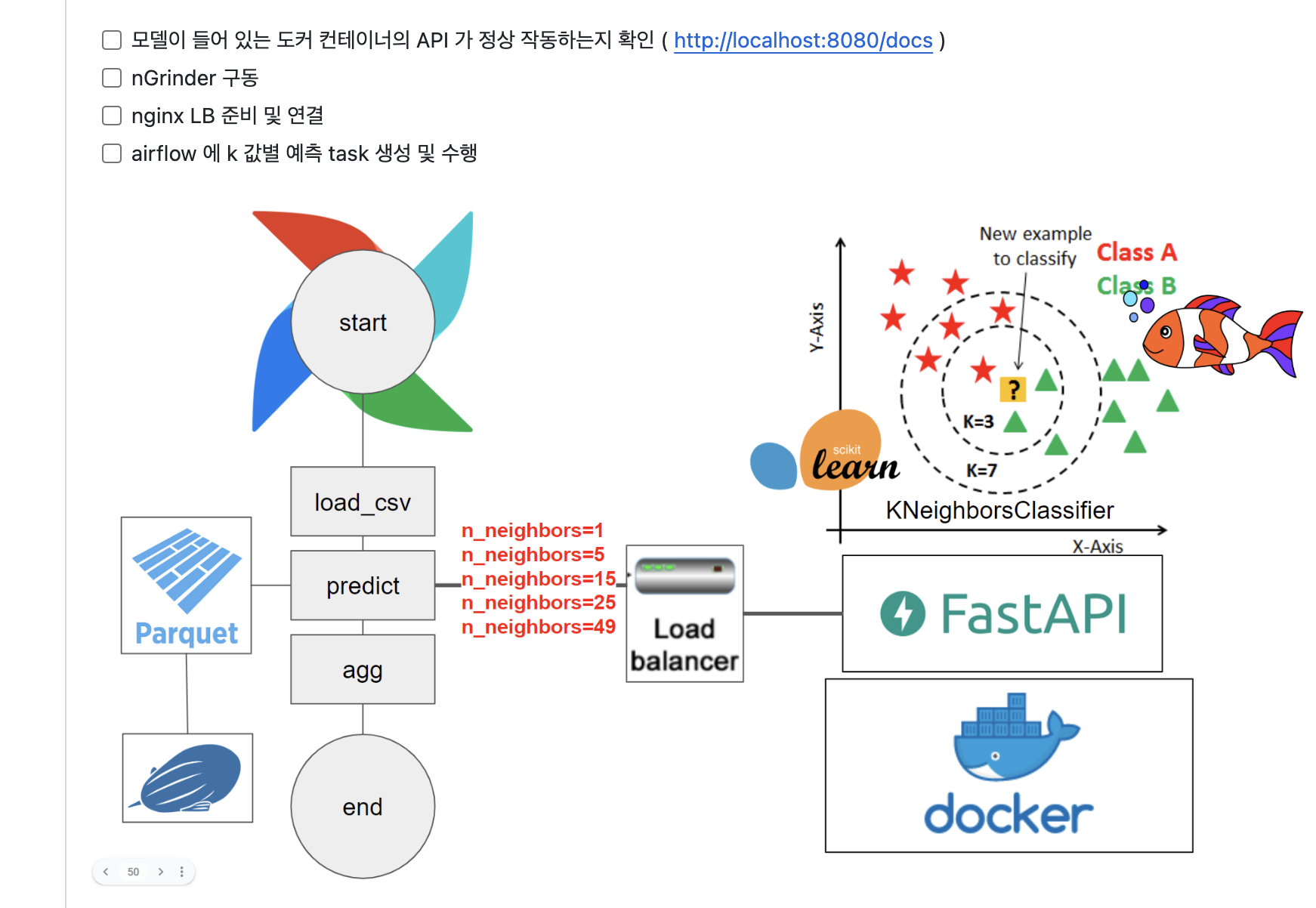
1) 받아오기
도커파일을 통해 (FROM ~ ) 도커허브의 이미지를 받아오거나, pull 명령어를 통해 받아 올 수 있는 것 같다.
$ vi Dockerfile
FROM python:3.11
From datamario24/python311scikitlearn-fastapi:1.0.0
WORKDIR /code
COPY src/fishmlserv/main.py /code/
RUN pip install --no-cache-dir --upgrade git+https://github.com/S00zzang/fishmlserv.git@0.8/hub
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8080"]
~$ docker pull datamario24/python311scikitlearn-fastapi:1.0.0
2) 올리기
$ docker build --no-cache -t <규칙에 따른 허브이름>
# docker build --no-cache -t sooj1n/fishmlserv:0.8.3 .$ docker login
Username: 비밀ㅎ
Password: 비밀ㅎ
$ docker push sooj1n/fishmlserv:0.8.3
1. cli 프로그램으로 모델 경로를 출력
$ cat pyproject.toml
[project.scripts]
get-model-path = 'fishmlserv.model.manager:get_model_path'$ docker build --no-cache -t fishmlserv:0.8.1 .
$ docker run -d -p 8081:8080 --name f081 fishmlserv:0.8.1
$ docker exec f081 get-model-path
/usr/local/lib/python3.11/site-packages/fishmlserv/model/model.pkl
2. 같은 방식으로 예측하는 cli
$ cat pyproject.toml
[project.scripts]
prediction = 'fishmlserv.model.manager:prediction'$ cat src/fishmlserv/model/manager.py
def prediction():
l = float(sys.argv[1])
w = float(sys.argv[2])
model_path = get_model_path()
### 모델 불러오기
with open(model_path, "rb") as f:
fish_model = pickle.load(f)
prediction = fish_model.predict([[l, w]])
p = fish_model.predict([[l, w]])
if p[0] == 1:
fish_class = "도미"
else:
fish_class = "빙어"
return fish_class$ docker build --no-cache -t fishmlserv:0.8.2 .
$ docker run -d -p 8081:8080 --name f082 fishmlserv:0.8.2
$ docker exec f081 prediction 25 50
도미
1. nGrinder
ngrinder 사용하려면 자바 버전을 11로 바꿔주고 실행해야한다. 오랜만에 실행하려니 기억이 안나서 다시 기록
# 자바 버전 바꾸기
$ vi .zshrc
# JAVA_HOME
#export JAVA_HOME=/usr/lib/jvm/java-17-openjdk-amd64
#export PATH=$JAVA_HOME/bin:$PATH
# nGrinder
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export PATH=$JAVA_HOME/bin:$PATH
# 실행
$ cd ~/app/ng/ngrinder-controller
$ java -jar ngrinder-controller-3.5.9-p1.war
$ cd ~/app/ng/ngrinder-agent
$ ./run_agent.sh
* 사소한거긴 한데 nGrinder에서 주소를 입력할 때 localhost는 알아먹지 못한다..
http://localhost:8100/fishlength=25&weight=100 ⇒ http://127.0.0.1:8100/fishlength=25&weight=100
이걸 하면서 계속 이해가 안됐던게 굳이 Fastapi에 값을 입력하는 부하를 계속 주는 이유가...///,,,,??@@
물어물어 해결했는데, 모델을 배포하기 전에 엄청난 수의 데이터를 예측해야 할 수도 있으니 그거에 대한 테스트라고 했다!
항상 나는 이런 이해가 부족한 듯 하다.

* 약간의 성능 개선
기존에는 prediction 함수 내에서 모델을 불러와서 한 번 호출할 때 마다 모델을 가져와서 사용했다.
이 부분을 함수 밖으로 빼서 한 번 만 호출하도록 수정했다.
나는 테스트를 돌려보지 못했지만, 다른 분들의 테스트 결과로 봤을 때, TPS가 더 높아진 것을 확인할 수 있었다.
$ cat src/fishmlserv/model/manager.py
model_path = get_model_path()
### 모델 불러오기
with open(model_path, "rb") as f:
fish_model = pickle.load(f)
def prediction():
l = float(sys.argv[1])
w = float(sys.argv[2])
prediction = fish_model.predict([[l, w]])
p = fish_model.predict([[l, w]])
if p[0] == 1:
fish_class = "도미"
else:
fish_class = "빙어"
return fish_class
2. LB
LB란 여러 대의 Server에게 균등하게 Traffic을 분산시켜주는 역할을 하는 것 이었다.

로컬에 있는 default.conf 파일을 컨테이너 안의 /etc/nginx/conf.d/ 경로에 복사하는 것 이다. 이는 NGINX의 기본 설정 파일을 덮어쓴다.
$ vi LB/Dockerfile
FROM nginx:1.25.1
COPY default.conf /etc/nginx/conf.d/
그리고 default.conf 파일은 이렇게 작성했다. 두 개의 서버(ml-1, ml-2)로 요청한다는 코드이다.
$ vi LB/default.conf
upstream ml_servers {
server ml-1:8080;
server ml-2:8080;
}
server {
listen 80;
location / {
proxy_pass http://ml_servers;
}
}
그러고나서 이렇게 실행시켰다. (이해하기 완전 어려웠음 !!)
$ docker build -t ml-lb:1.5.0 LB/
$ docker run -d --name ml-1 sooj1n/fishmlserv:0.8.3
$ docker run -d --name ml-2 sooj1n/fishmlserv:0.8.3
$ docker run -d --name ngix_lb-2 -p 8765:80 --link ml-2 --link ml-1 ml-lb:1.5.0

어떻게 이해했냐면, 먼저 이 사진을 보면 두 이미지는 크기가 다르다. 주 컨텐츠가 들어있는 sooj1n/fishmlserv의 크기가 상대적으로 훨씬 큰데, 이렇게 큰 용량의 이미지를 계속해서, 반복해서 로드하여 사용하기에는 부하가 크기 때문에 ml-lb라는 껍데기를 빌드했다.
그리고 주 컨텐츠인 이미지(sooj1n ~ )를 통해 컨테이너를 두 개(ml-1, ml-2) 실행하였다.
그리고 마지막으로 ml-1과 ml-2를 link 한 ngix_lb-2 컨테이너를 8765 포트로 만든 것 이다.
nGrinder에서 8765 포트로 테스트하며 아래의 명령어로 cpu 사용량 등을 확인할 수 있다.
$ docker stats

결과, ngix_lb-2, ml-1, ml-2가 골고루 실행되는 것을 확인할 수 있다.
실습을 위해 ng, lb, ml(3개) 이렇게 총 5개의 서버를 받았다.
나는 ng 서버를 담당해서 설치 및 테스트를 수행했다.
처음에는 ml 서버 당 10개의 도커를 run 해서 lb 에서 총 30개의 도커를 부하분산 시키려고 했다. 근데 그렇게 하니까 과부화가 와서 서버가 다운 돼버렸다. 강사님이 ml 서버 당 1개의 도커를 빌드하라고 하셨다.
위에서는 --link 옵션으로 도커를 run 하였는데 그렇게 하지 않고,
$ vi LB/default.conf
upstream ml_servers {
# ml server 1
# ml server 2
# ml server 3
}
server {
listen 80;
location / {
proxy_pass http://ml_servers;
}
}이 파일에 서버 3개 주소를 입력하고 lb 서버에서 도커를 run 했다.
nGrinder를 통해 부하분산을 테스트 한 결과는 다음과 같다.
- c3
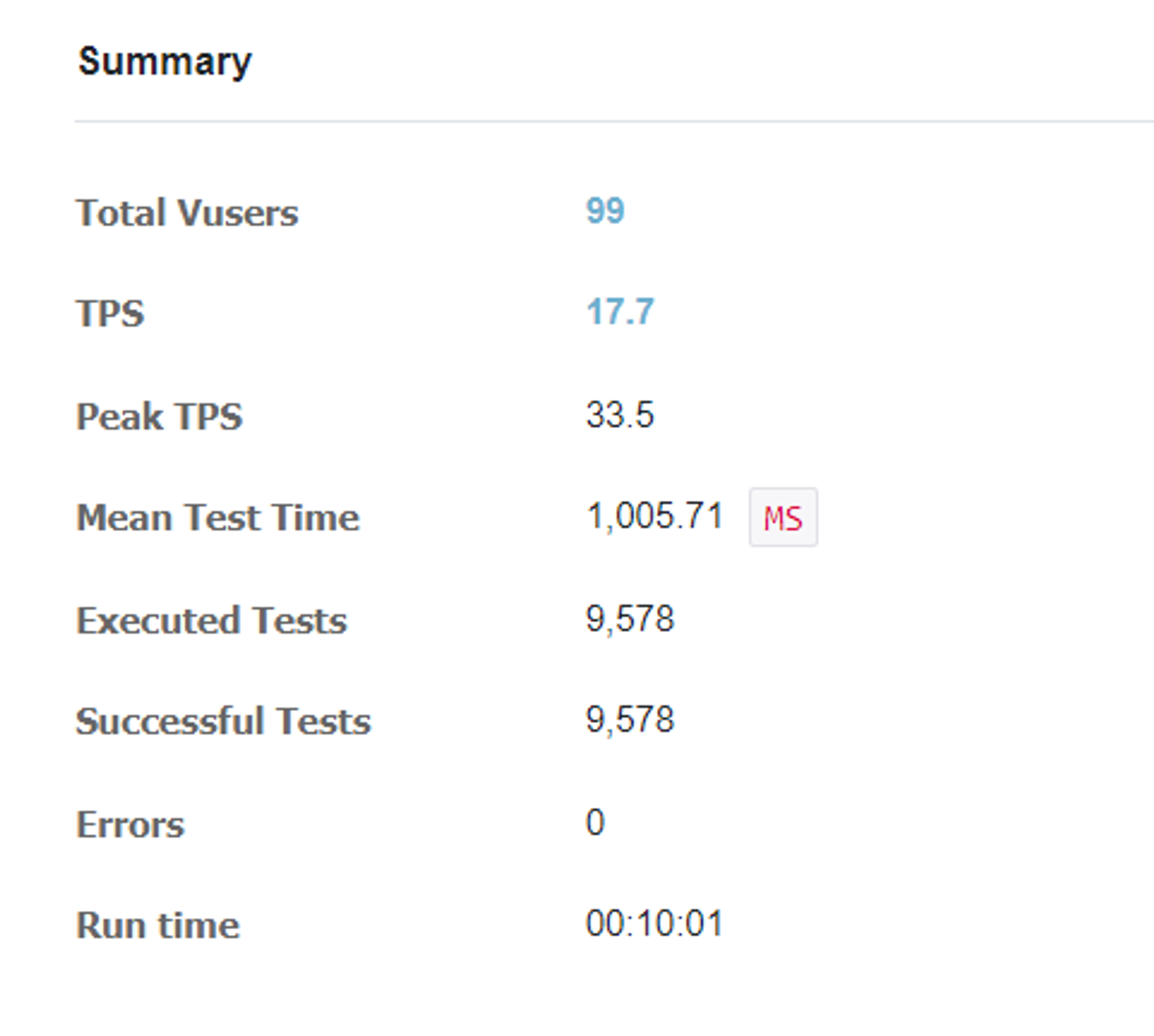
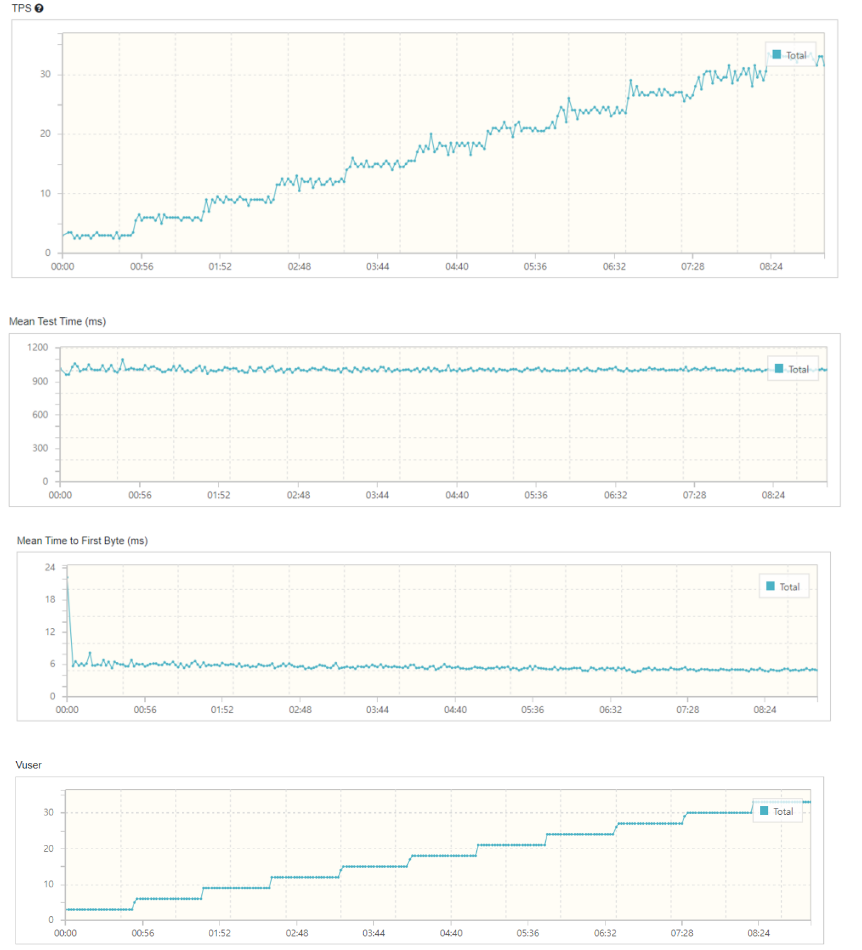
-c2
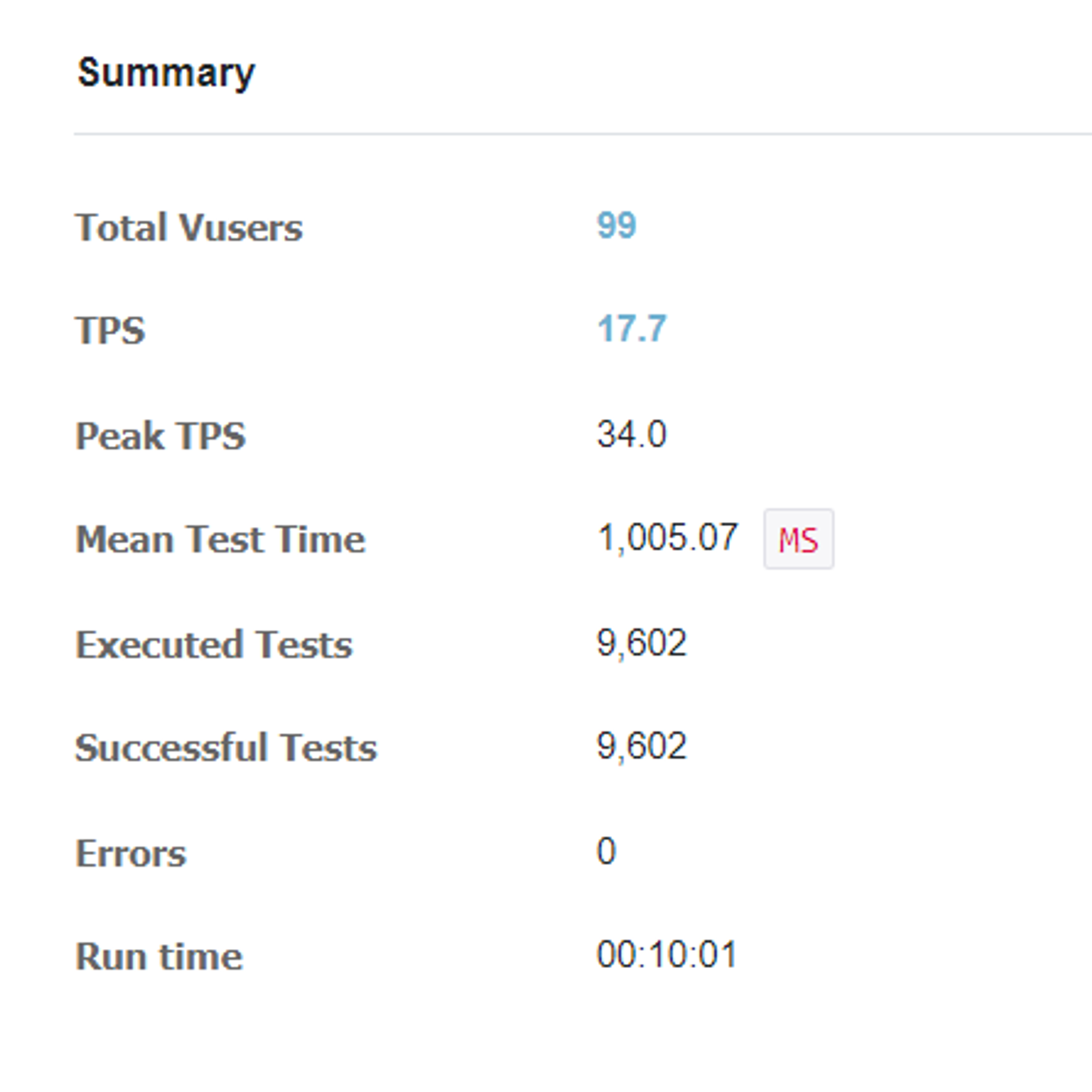
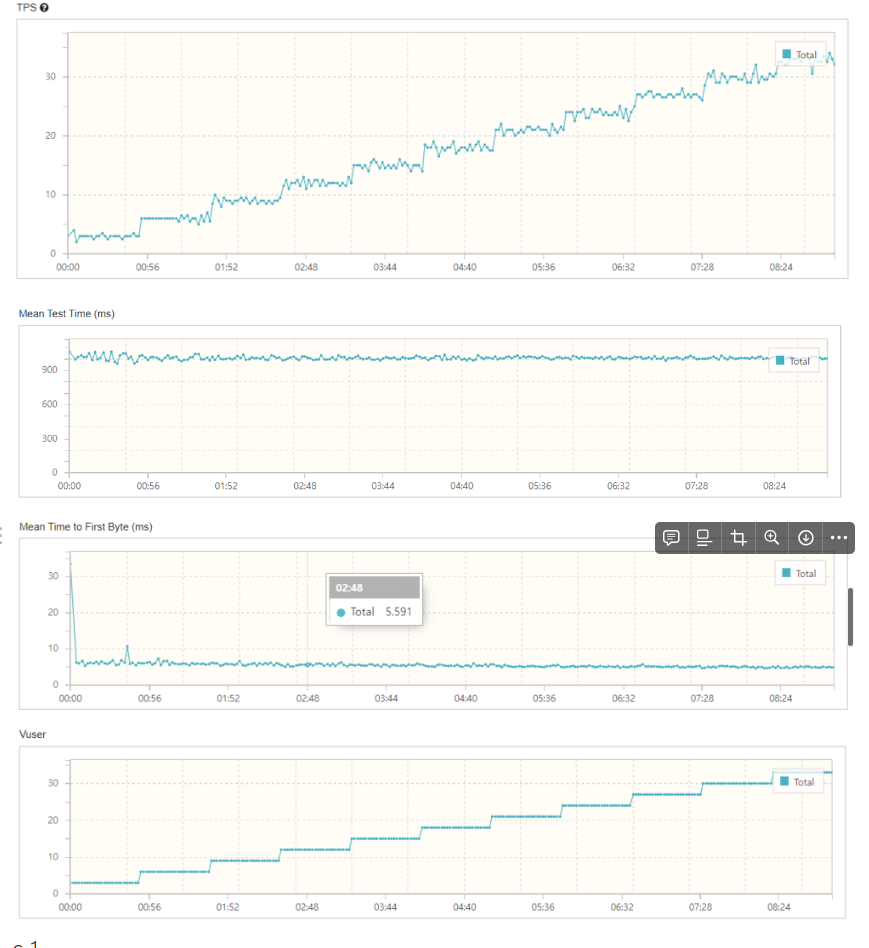
-c1
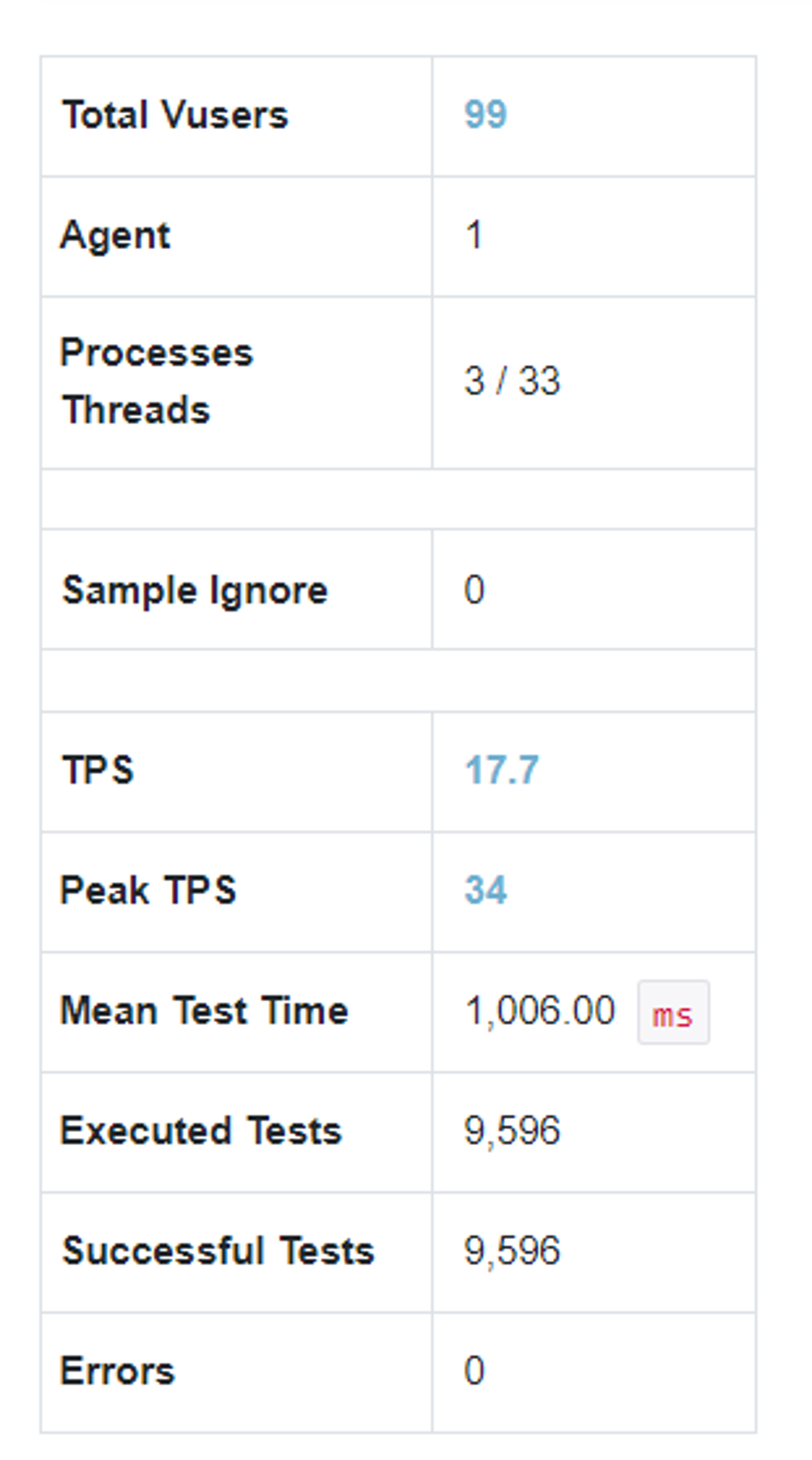
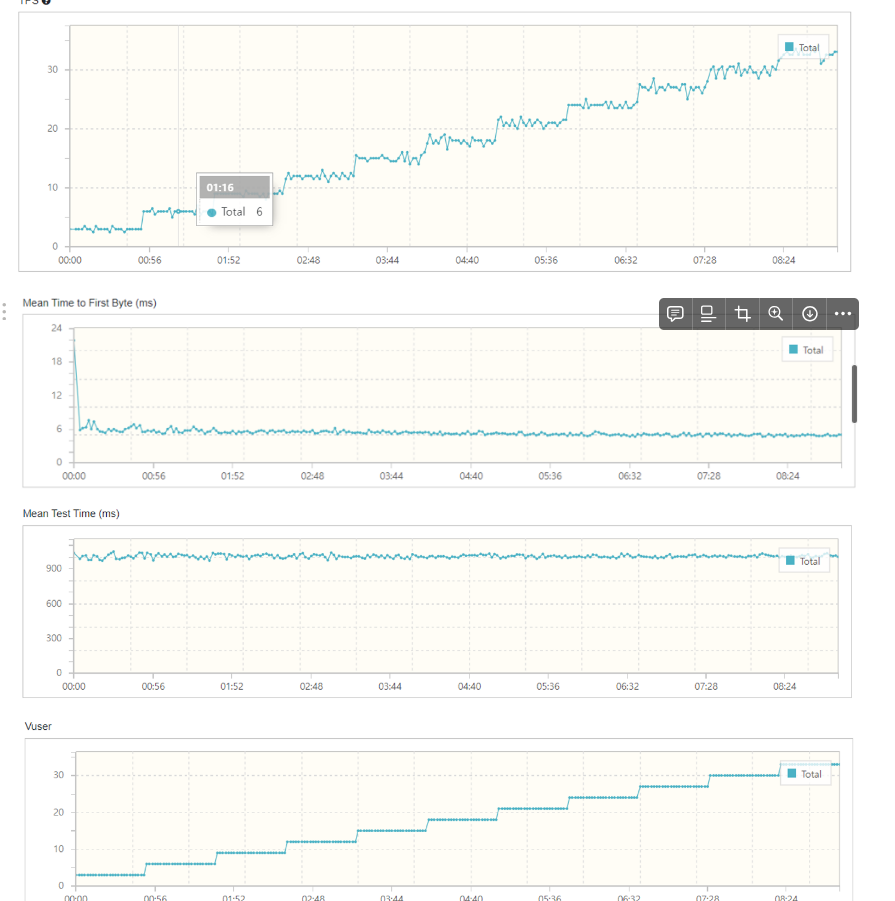
근데 다른 팀 들은 서버 수에 따라 테스트 결과에 차이가 좀 있었는데, 우리 팀은 별 차이 없었다.
테스트 값을 다르게 줘 봤다면 차이가 있었을 수도 ?
이유는 모르겠심다..
🥹 아쉬웠던 점
사실 이번 주는 많이 아쉬웠던 한 주 였는데, 뭔가 배우는 느낌 보다는 강사님이 이해를 돕기 위해서인지 실습을 계속 주셔서(좀 오랜 시간..) 날리는 시간이 많았던 느낌이다! 지금 뭐하는거임(?) 이라는 대화를 계속 했다.
💪 이 상태에서 다음 일주일을 더 잘 보내려면 어떻게 해야 할까?
시간이 남을 때 그냥 쉬면서 놀았었는데, 그러다보니 배우러와서 시간을 더 버린 느낌이었다.그 시간에 회고를 쓰던지 복습하는 시간을 가져야겠다.
'playdata > weekly' 카테고리의 다른 글
| [플레이데이터 데이터 엔지니어링 캠프 32기] 11주차 회고 (0) | 2024.09.23 |
|---|---|
| [플레이데이터 데이터 엔지니어링 캠프 32기] 10주차 회고 (0) | 2024.09.23 |
| [플레이데이터 데이터 엔지니어링 캠프 32기] 8주차 회고 (3) | 2024.09.01 |
| [플레이데이터 데이터 엔지니어링 캠프 32기] 7주차 회고 (1) | 2024.08.24 |
| [플레이데이터 데이터 엔지니어링 캠프 32기] 6주차 회고 (1) | 2024.08.18 |